经过一系列优化修改后,网站测速评分总算是过得去了。😄使用技术大概有如下:
- 各种CDN
- webp
- lazyload
- preload
- gulp 压缩
- cloudflare parter
- service worker, PWA
- 部分资源异步加载
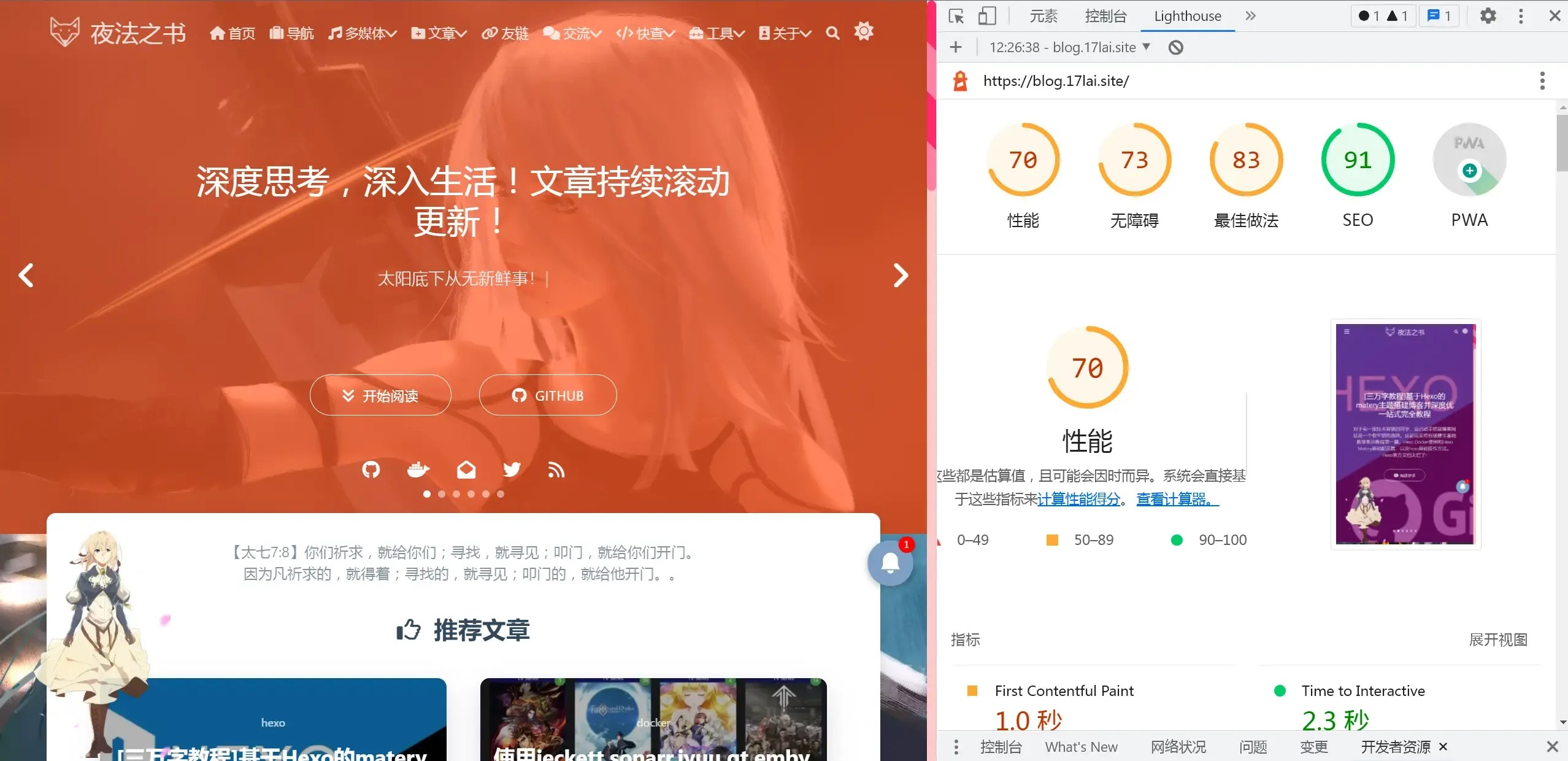
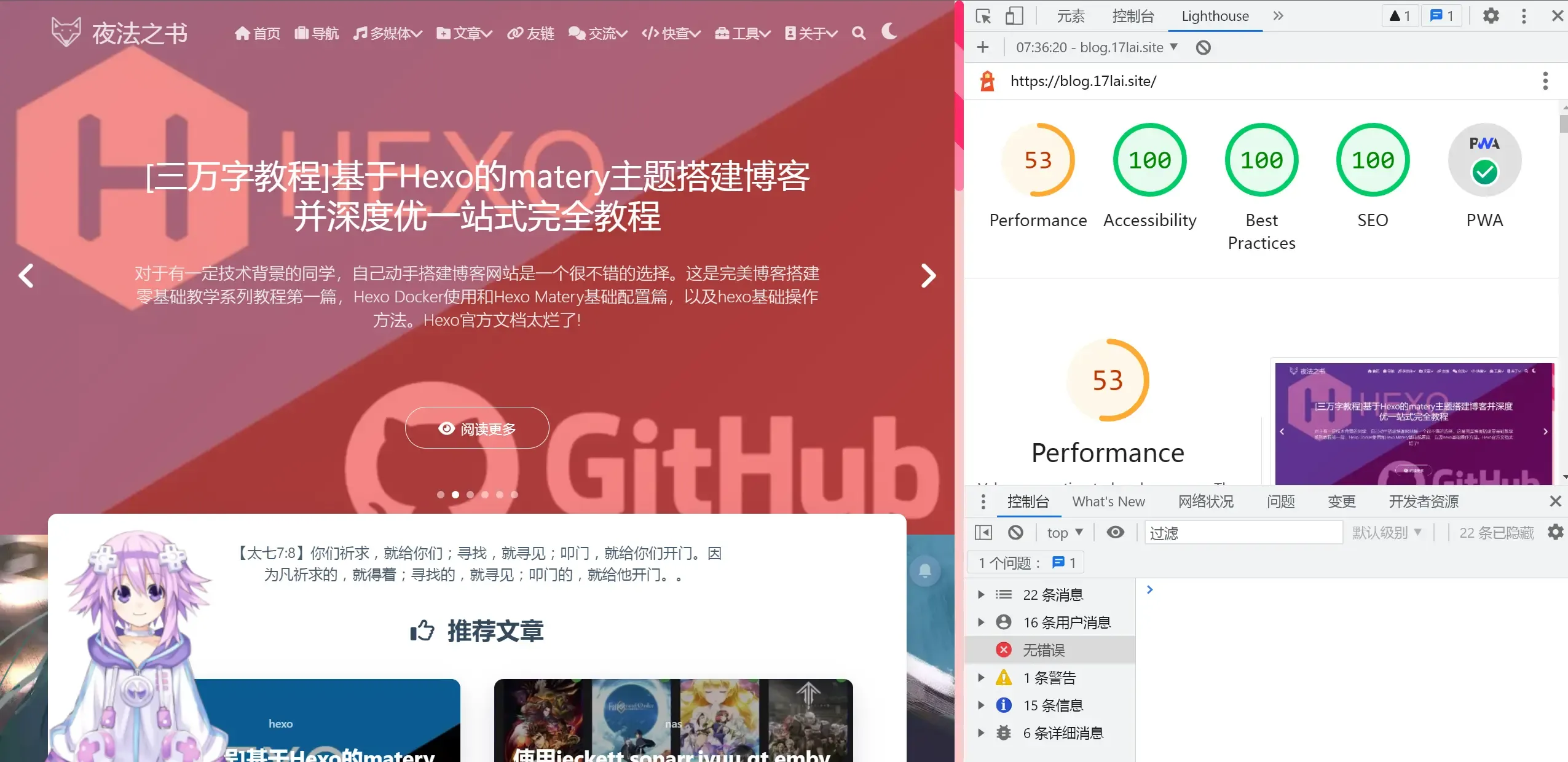
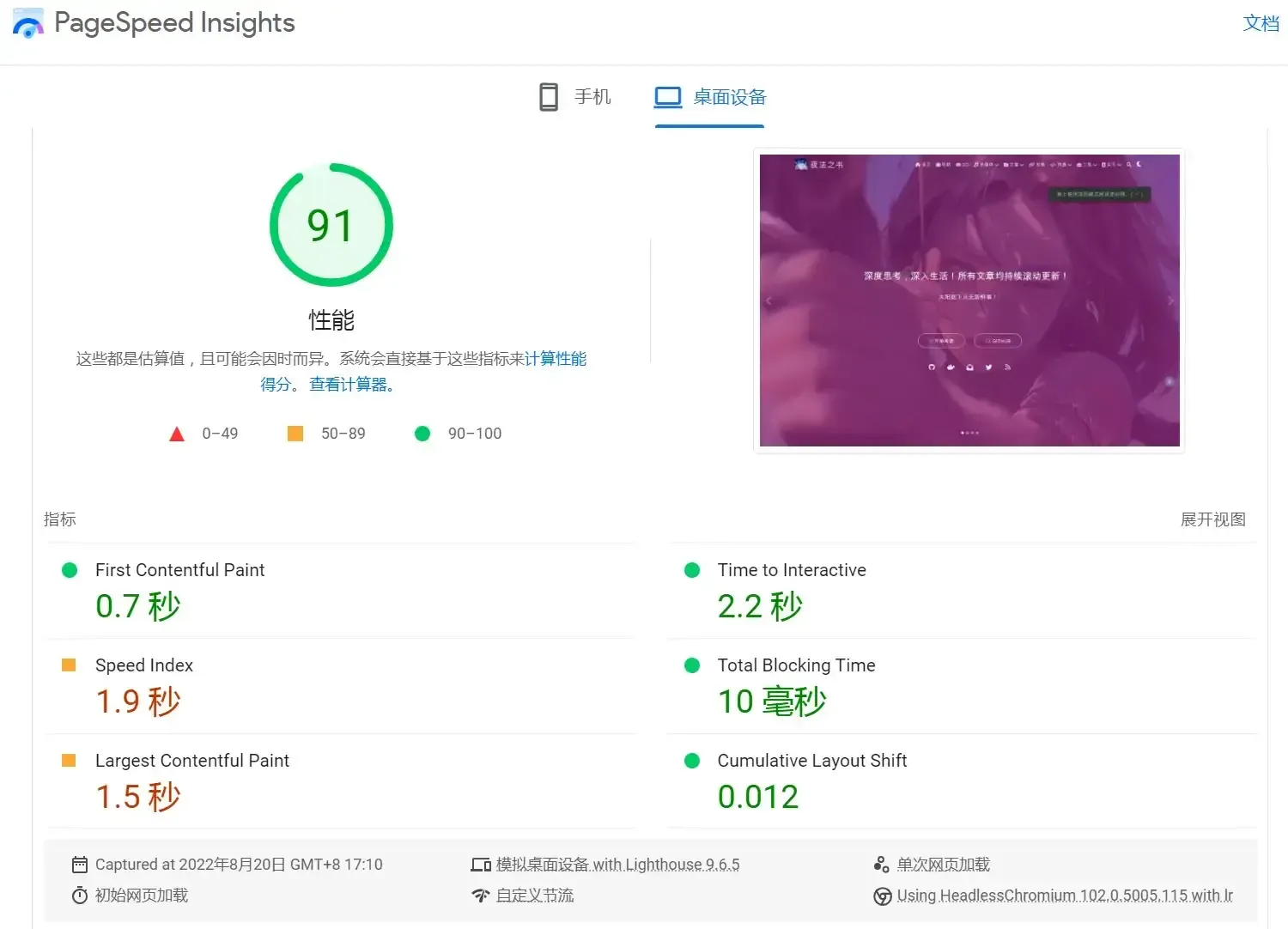
优化无止境,每当以为只能上钞能力的时候,又发现了新的优化方法!
看来,钞能力还得保留一整子了~
加载速度优化概要
性能优化
浏览器渲染网页的过程可以参考这篇文章 在浏览器输入 URL 回车之后发生了什么
前端性能优化作为前端开发中的一项系统化工程,不仅仅是提升页面加载速度或减少资源大小,它涵盖了从网络请求、资源加载、代码执行到页面渲染等多个环节的优化策略,是一个复杂且系统化的工程。然而,在实际开发过程中,许多开发者往往只关注某些局部的优化点,如压缩图片、减少HTTP请求等,而缺乏对性能优化全局的把握。这种碎片化的优化方式虽然能在一定程度上提升性能,但往往难以达到最佳效果,甚至可能引入新的性能瓶颈。
因此,掌握前端性能优化的全局视角,理解各个环节的优化原理与实践方法,是每一位前端开发者必须面对的重要课题。本文将从性能优化的核心目标出发,探索性能优化的整个流程的核心关键节点以及其优化手段,帮助开发者建立起系统化的性能优化思维。
整体流程
前端性能优化的核心目标是提升用户从输入 URL 到最终看到完整页面并与之交互的体验。这一过程可以概括为三个主要环节:从用户输入 URL 到资源加载完成、浏览器解析与渲染网页、JavaScript 脚本执行。每个环节都涉及不同的性能瓶颈和优化机会,只有系统性地分析并优化这些环节,才能真正提升前端性能。
输入URl到请求结束的流程
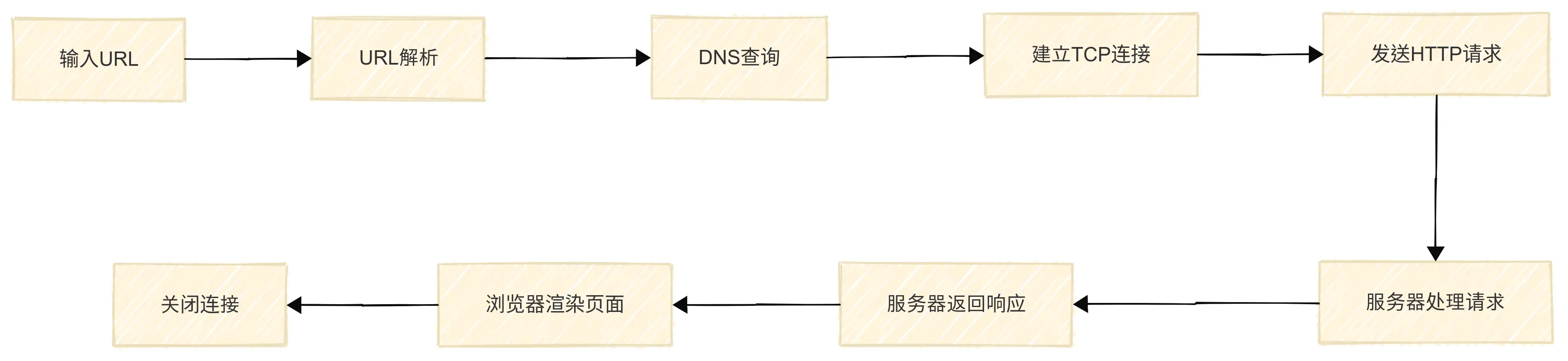
- 输入URL
- URL解析
- DNS查询
- 建立TCP连接
- 发送HTTP请求
- 服务器处理请求
- 服务器返回响应
- 关闭连接
通过思维导图,再看看其中的详细过程
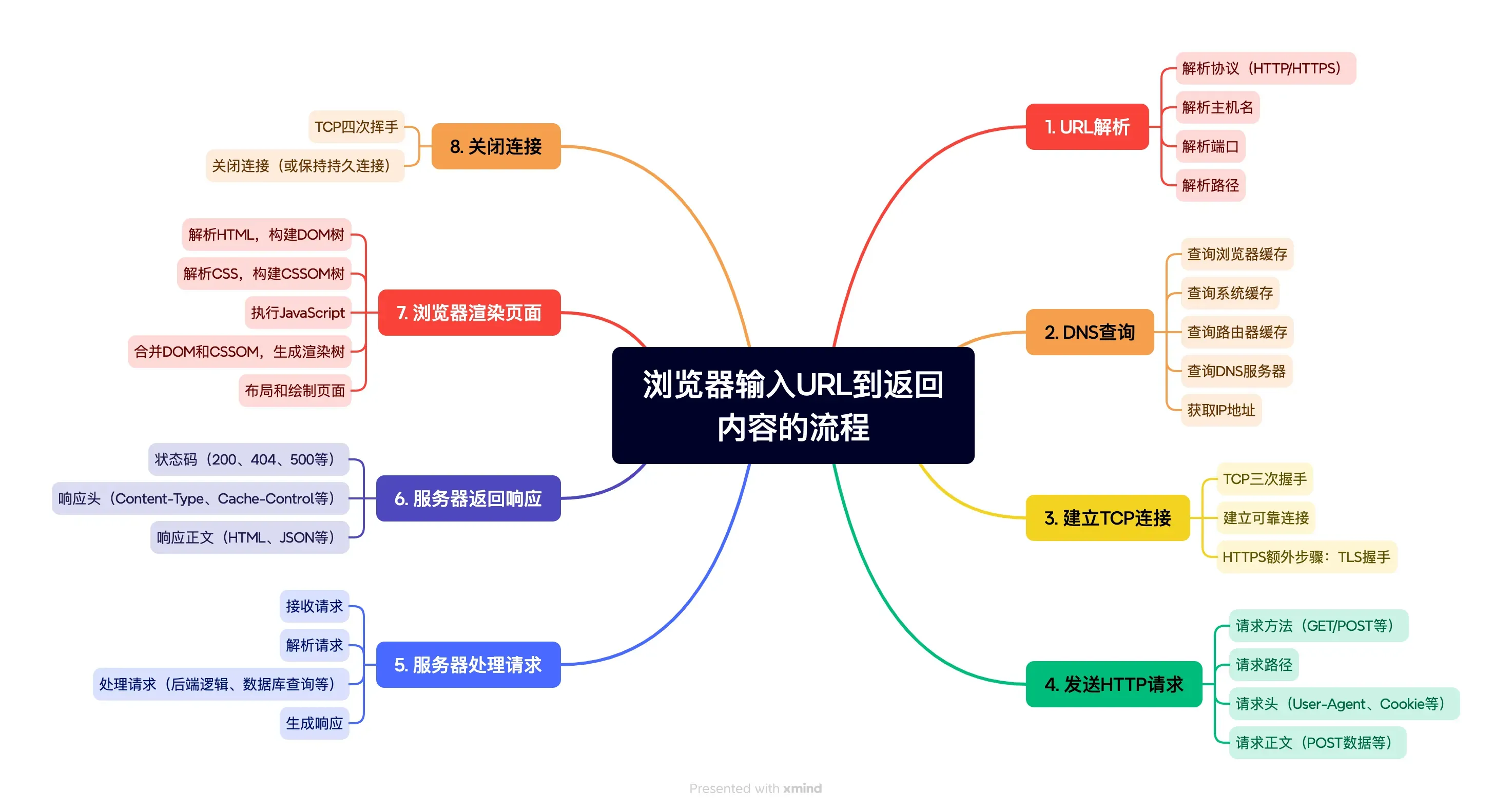
网络请求优化
当用户在浏览器地址栏输入 URL 并按下回车键后,浏览器会经历一系列步骤,包括 DNS 解析、建立 TCP 连接、发送 HTTP 请求、等待服务器响应,以及最终将资源(如 HTML、CSS、JavaScript 等)下载到本地。
这一过程的核心是从用户发起请求到浏览器接收到完整的资源数据,其效率直接影响页面的首次加载时间(First Contentful Paint, FCP)。
优化这一环节的关键在于减少网络延迟、压缩资源体积、利用缓存机制以及优化服务器响应时间。把这些点总结一下可以分两个思路:网络链路加速和网络负载体积减少
渲染优化
当浏览器接收到 HTML、CSS、JavaScript 等资源后,会开始解析和渲染页面。这个过程包括构建 DOM 树、CSSOM 树、合并生成渲染树(Render Tree),以及进行布局(Layout)和绘制(Paint)。浏览器解析和渲染的效率直接影响页面的交互性和流畅度。
优化这一环节的关键在于减少渲染阻塞资源、优化 CSS 和 HTML 结构、避免不必要的重排(Reflow)和重绘(Repaint)以及GPU加速等。
JS 执行优化
JavaScript 是前端交互的核心,但它的执行效率直接影响页面的响应速度和用户体验。JavaScript 的解析、编译和执行可能会阻塞主线程,导致页面卡顿或无响应。
优化这一环节的关键在于 减少 JavaScript 文件大小、避免长任务(Long Tasks)、优化代码执行效率,以及合理使用 Web Workers 等技术来分担主线程的压力。以下是几种常见的优化方法:
使用 async 和 defer 加载脚本
JavaScript 默认是 同步加载并执行 的,会阻塞 HTML 解析,因此对于外部脚本文件,推荐使用 async 或 defer 来优化加载策略。
| 属性 | 执行顺序 | 是否阻塞 HTML 解析 | 适用场景 |
|---|---|---|---|
async | 下载完立即执行,多个 async 脚本执行顺序不固定 | 否 | 独立脚本,不依赖其他脚本(如广告、统计代码) |
defer | HTML 解析完后按顺序执行 | 否 | 依赖 HTML 结构或其他脚本(如主逻辑 JS 文件) |
✅ 示例
<!-- async:适用于无依赖的独立脚本 -->
<script async src="analytics.js"></script>
<!-- defer:适用于依赖 HTML 结构的脚本(推荐)-->
<script defer src="main.js"></script>代码拆分 & 按需加载
加载过多的 JavaScript 会拖慢页面速度,因此可以使用 代码拆分(Code Splitting)和 按需加载(Lazy Loading)减少主线程压力。
✅ 示例:使用 import() 进行动态加载
document.getElementById('loadFeature').addEventListener('click', async () => {
const { featureFunction } = await import('./featureModule.js');
featureFunction();
});- 只有用户点击按钮时才会加载
featureModule.js,减少初始加载时间。
避免长任务(Long Tasks)
长任务(执行时间超过 50ms 的任务)会导致页面卡顿,影响交互流畅性。可以使用 requestIdleCallback 或 setTimeout 将任务拆分成多个小块执行。
✅ 示例:使用 requestIdleCallback 让低优先级任务在空闲时间执行
requestIdleCallback(() => {
heavyTask(); // 仅在浏览器空闲时执行
});✅ 示例:使用 setTimeout 让任务拆分执行
function processLargeArray(arr) {
let i = 0;
function nextChunk() {
const start = performance.now();
while (i < arr.length && performance.now() - start < 50) {
processItem(arr[i]);
i++;
}
if (i < arr.length) {
setTimeout(nextChunk, 0);
}
}
nextChunk();
}- 每次执行 50ms,避免长时间阻塞主线程,提高页面流畅度。
使用 Web Workers 进行多线程计算
JavaScript 运行在 单线程环境 下,繁重的计算任务会导致页面卡顿。可以使用 Web Workers 将计算任务放到后台线程运行。
✅ 示例:使用 Web Worker worker.js
self.onmessage = function (event) {
const result = heavyComputation(event.data);
self.postMessage(result);
};主线程
const worker = new Worker('worker.js');
worker.postMessage(largeData);
worker.onmessage = function (event) {
console.log('计算结果:', event.data);
};- 计算任务在后台线程执行,主线程不会被阻塞,提高页面响应速度。
其他优化技巧
✅ 减少 JavaScript 体积
- 使用 Tree Shaking 移除无用代码(适用于 ES6
import/export) - 启用 gzip、Brotli 压缩(
Content-Encoding: gzip) - 使用 CDN 加速 静态资源加载
✅ 优化 DOM 操作
减少回流(Reflow)和重绘(Repaint)
使用
documentFragment进行批量 DOM 插入:
const fragment = document.createDocumentFragment(); for (let i = 0; i < 1000; i++) { const div = document.createElement('div'); div.textContent = `Item ${i}`; fragment.appendChild(div); } document.body.appendChild(fragment);
✅ 使用 requestAnimationFrame() 提高动画流畅度
function smoothScroll() {
requestAnimationFrame(smoothScroll);
}
smoothScroll();总结
| 优化方法 | 关键点 |
|---|---|
async & defer | async 适用于无依赖脚本,defer 适用于依赖 HTML 的脚本 |
| 代码拆分 & 按需加载 | 仅在需要时加载 JavaScript |
| 避免长任务 | 使用 requestIdleCallback 或 setTimeout 拆分任务 |
| Web Workers | 将 CPU 密集型任务放到后台线程 |
| 压缩 JavaScript | 使用 Tree Shaking、Gzip/Brotli 压缩 |
| 优化 DOM 操作 | 减少回流 & 使用 documentFragment |
合理使用这些技术,可以有效提升 JavaScript 执行效率,提高页面流畅度 🚀
网络链路优化
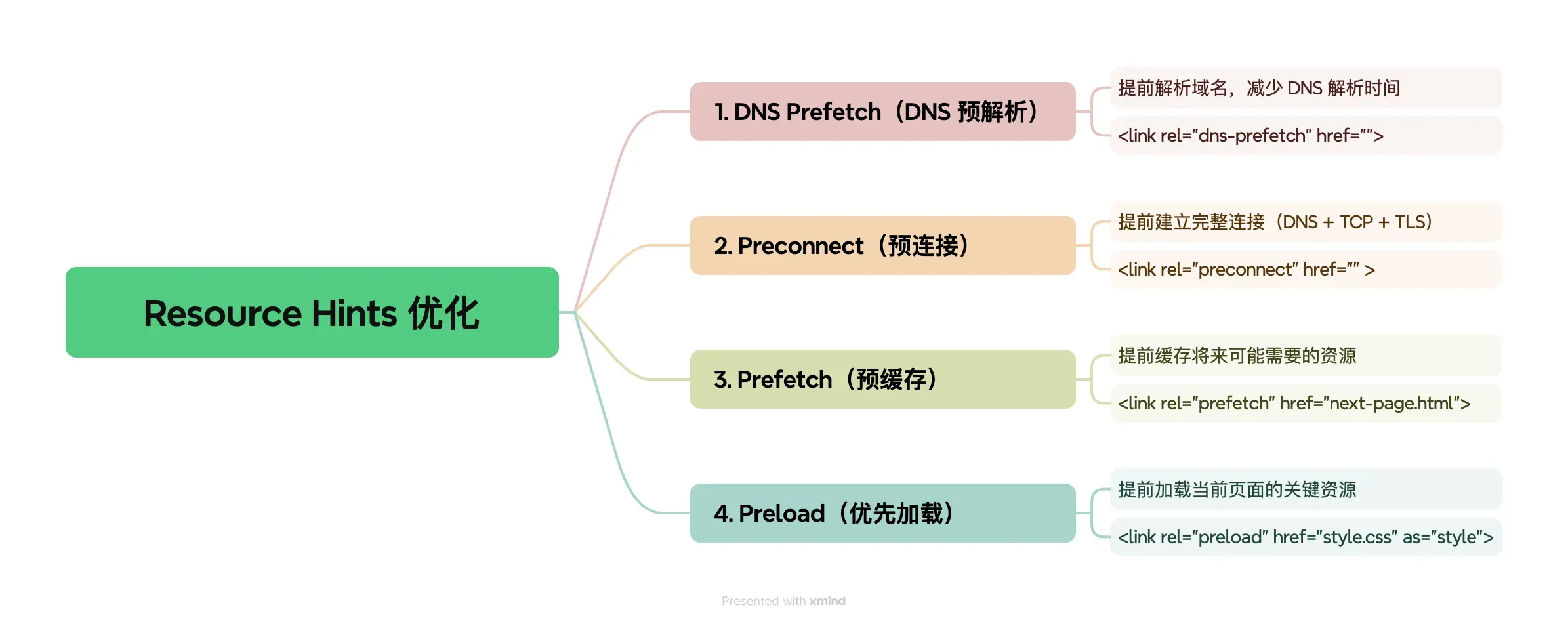
DNS 预解析 – dns-prefetch
通过在页面加载初期就解析可能需要的域名,当实际需要加载这些域名的资源时,DNS 解析已经完成,从而加快资源的加载速度。这个标签对于 CDN 域名等非主域名提前解析 CDN ,有很大的帮助,强烈建议添加。
dns-prefetch 可以通过 <link> 标签在 HTML 中声明,或者通过 HTTP 头部进行配置。
<head>
<link rel="dns-prefetch" href="https://blog.17lai.site">
</head>HTTP 预连接 – preconnect
preconnect 用于提前建立与目标域名的连接,包括 DNS 解析、TCP 握手和 TLS 协商。这比 dns-prefetch 更全面,适用于需要更早建立连接的场景。
使用方法和 dns-prefetch 类似
<head>
<link rel="preconnect" href="https://blog.17lai.site" crossorigin>
<head>内容预加载 – prefetch
prefetch 是一种资源提示,它告诉浏览器在空闲时间提前下载并缓存将来可能需要的资源。这可以显著减少用户请求这些资源时的等待时间,从而提高用户体验。
使用场景:
- 当您预测用户可能会导航到另一个页面或执行某个操作时,可以提前预加载该页面或操作所需的资源。
- 对于单页应用(SPA),预加载用户可能访问的下一个视图或组件可以显著提高性能。
使用方法:
<head>
<!-- 预加载整个页面 -->
<link rel="prefetch" href="next-page.html">
<!-- 预加载特定资源,如图片、脚本或样式表 -->
<link rel="prefetch" href="image.png" as="image">
<link rel="prefetch" href="script.js" as="script">
<link rel="prefetch" href="styles.css" as="style">
</head>注意事项:
- 不要过度使用
prefetch,因为它可能会浪费带宽和资源,特别是当预加载的资源最终未被使用时。
优先加载 – preload
preload 是一种更强大的资源提示,它告诉浏览器立即请求并缓存特定资源,以便在需要时立即使用。与 prefetch 不同,preload 更侧重于当前页面渲染所需的资源,而不是将来可能需要的资源。
使用场景:
- 当您知道某个资源对当前页面的渲染至关重要,并且希望确保它在需要时立即可用时,可以使用
preload。 - 对于关键路径上的资源,如关键的 CSS、JavaScript 或字体文件,
preload可以显著提高页面加载性能。
使用方法:
<head>
<!-- 立即加载 CSS -->
<link rel="preload" href="styles.css" as="style">
<link rel="stylesheet" href="styles.css">
<!-- 立即加载 JavaScript -->
<link rel="preload" href="main.js" as="script">
<script src="main.js"></script>
<!-- 立即加载 -->
<link rel="preload" href="font.woff2" as="font" type="font/woff2" crossorigin>
</head>注意事项:
preload的资源会被浏览器优先加载,这可能会影响其他资源的加载顺序和性能。
以上四种优化方式我们同程为 resource hints
资源缓存
通过http的缓存能力,将资源缓存到浏览器端,可以直接从浏览器拿取内容,不经过服务器,或者经过浏览器,浏览器返回 304,告诉浏览器直接使用缓存,不用下载。
缓存常用的 http header 包括,cach-control 和 expire 。这里内容较多,暂不展开,之后详细介绍
升级 HTTP 协议
HTTP 协议,主要包括HTTP/1.1、HTTP/2和HTTP/3。高版本在性能、安全性和功能上进行了优化和改进。能使用高版本,尽量使用高版本,同时做好兼容性配置。下面是几个版本的核心能力
| HTTP 版本号 | 核心功能 |
|---|---|
| HTTP/1.1 | 引入持久连接和管道化,提升了连接复用和传输效率,但存在队头阻塞问题 |
| HTTP/2 | 采用二进制协议和多路复用,消除了队头阻塞,引入头部压缩和服务器推送,显著提升了性能和效率。 |
| HTTP/3 | 基于QUIC协议,进一步优化了连接建立速度、传输效率和安全性,解决了TCP的一些固有问题,提供了更好的用户体验。 |
减少网络负载
网络传输协议压缩
开启 gzip 和 Brotli 压缩
在服务端放置 gzip 压缩后的文件,开启 gzip 之后,可以直接发送 gzip 文件,浏览器端会自动解析 gzip。
Brotli 和 gzip 一样的压缩策略,只不过压缩比更高,后来居上,但是兼容性不好,使用 brotli 需要考虑兼容性
资源内容压缩
JS 和 CSS 压缩
通过打包工具,去掉注释,空格,各种名称精简等方式,将 js 和 CSS 压缩到更小的体积,
图片压缩
图片大小优化有两个方向:
- 通过压缩算法,将图片压缩到更小的体积,常用的网站如:https://tinify.cn/
- 转换图片格式,获得更小的体积。比如 jpg 转 png,png 转 webp等,webp 有更小的体积,但要考虑兼容性问题。
利用 tree shaking
使用第三方库时,经常会将所有代码引入进来,但是只用到其中的很少的功能。因此,通过打包工具,开启tree shaking,可以有效减少生成代码的体积。
开始tree shaking 的优化
代码拆分
不同页面有不同的功能,代码逻辑不同。因此,在加载首页时,非必要的内容就不要加载,减少首次加载的资源的体积。
网站测速工具
网站打开速度已经成为 SEO 重要的排名依据,除了上面说到的人肉测试,就面向国内用户 + 加载速度测试场景而言,推荐以下三款工具:
IPIP.NET TraceRoute 查询
IPIP.NET 是一家专注 IP 地理位置以及 IP 画像数据的研究、整理与发行的数据公司,提供 TraceRoute 等一系列 IP 相关的在线工具。使用 Trace 的方式可以查看用户到站点的路由信息,一般来说跳数越少打开速度越快,选择 IPIP.NET 是因为其 TraceRoute 提供了可视化的效果,一眼看清问题所在。
Pingdom Website Speed Test
知名的网站测速工具,相比 Google PageSpeed Insights 不能指定测速节点,它可以指定从全球数个节点发起测试请求,更贴近你的用户群体。
亚洲这边只有东京区域,四舍五入一下我选择东京区域来测试好了。
其它还有
加载速度评估
要想优化加载速度,我们首先要通过一些方法量化分析网站加载速度,这样才能更好的对加载速度进行优化。以下是常用的一些分析网站加载速度的工具。
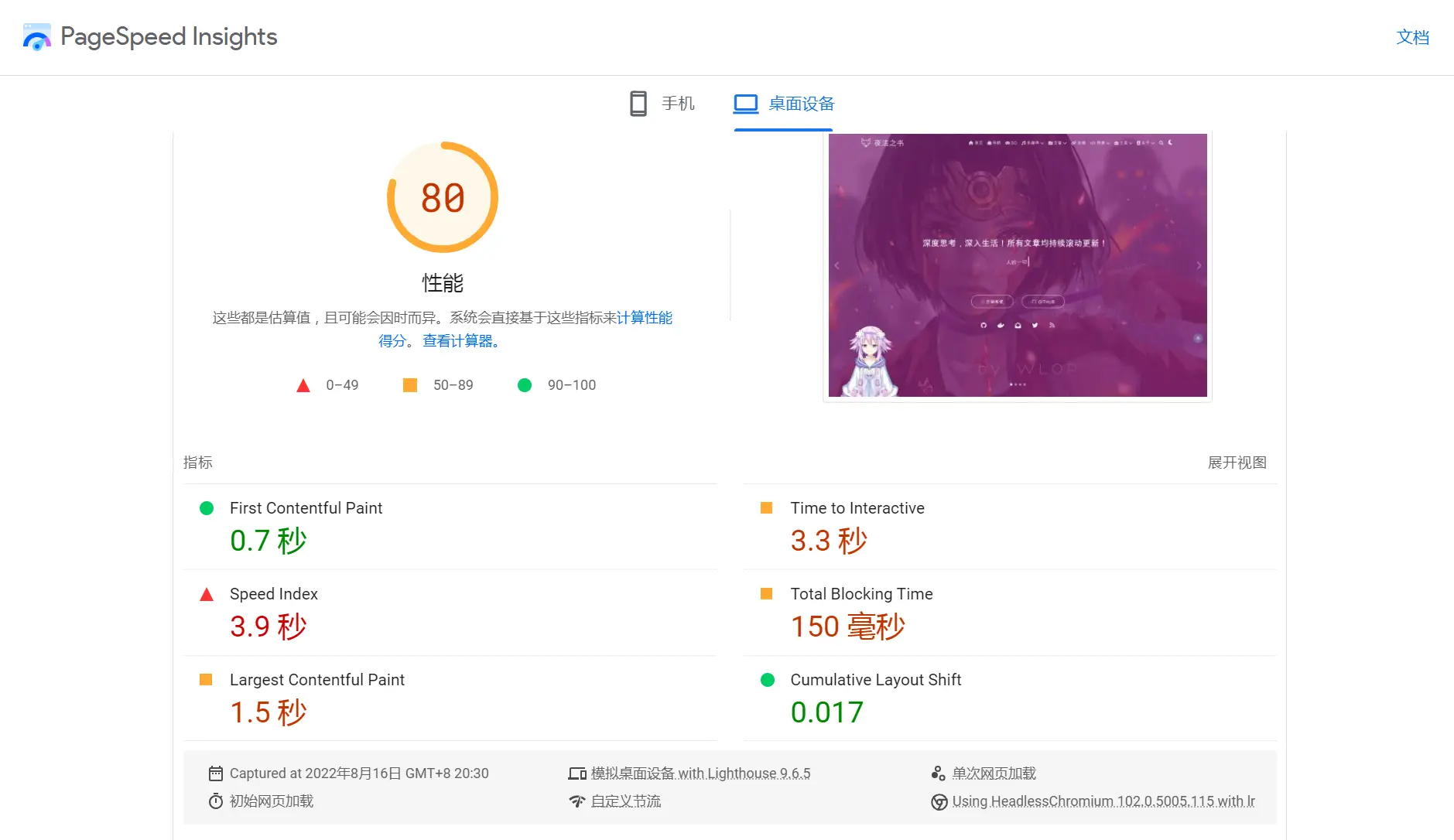
Google PageSpeed Insights
PageSpeed是检测网站加载速度很重要的工具,它可以给予我们非常详细的优化点,从中可以发现拖慢网站的元凶。
移动设备适合性测试
https://search.google.com/test/mobile-friendly?hl=zh_CN
experte pagespeed
https://www.experte.com/pagespeed 一次自动化测试多个网页评分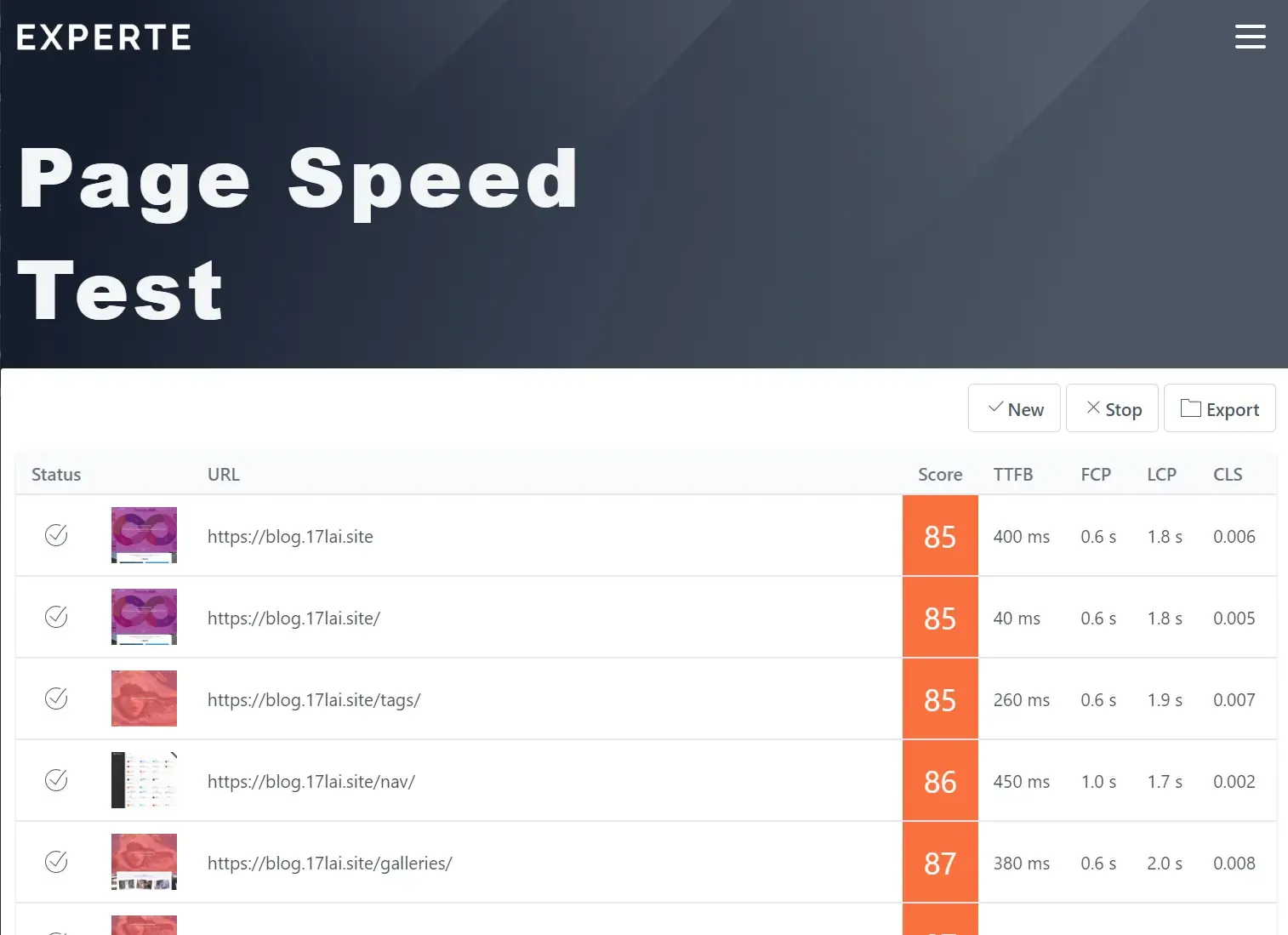
Chrome Audits(Lighthouse)
现代浏览器都自带性能测试工具,例如 Chrome, firefox,打开网页, 按 F12 键即可调出测试工具!
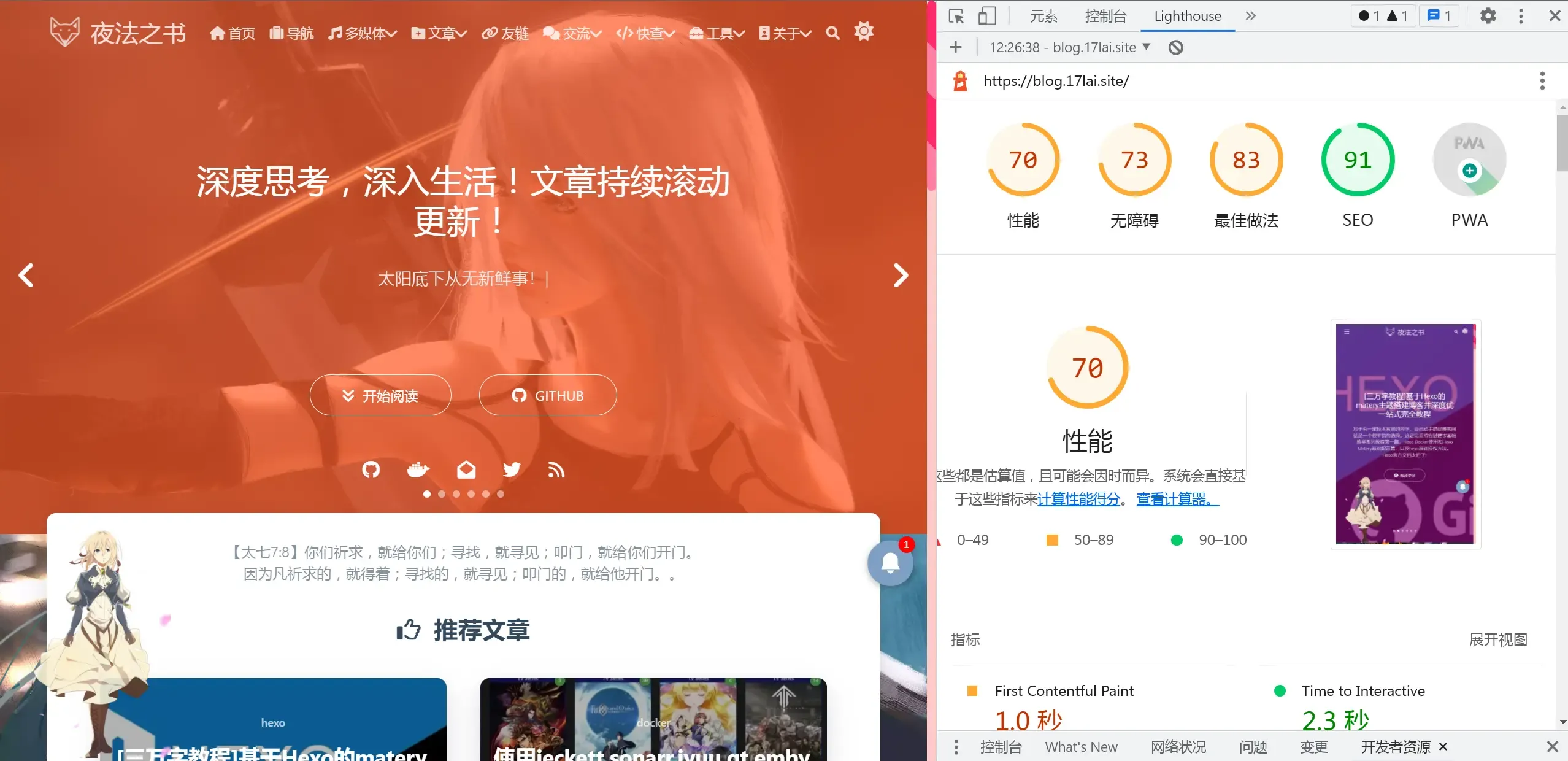
Chrome浏览器自带的Audits除了能让我们查看网站的加载速度,还可以查看网站最佳实践、可用性、SEO及PWA方面的评分及改进点。如果你的网站在这几方面评分都超过90分,那一定是Google在这几方面很喜欢的网站了。
webpagetest
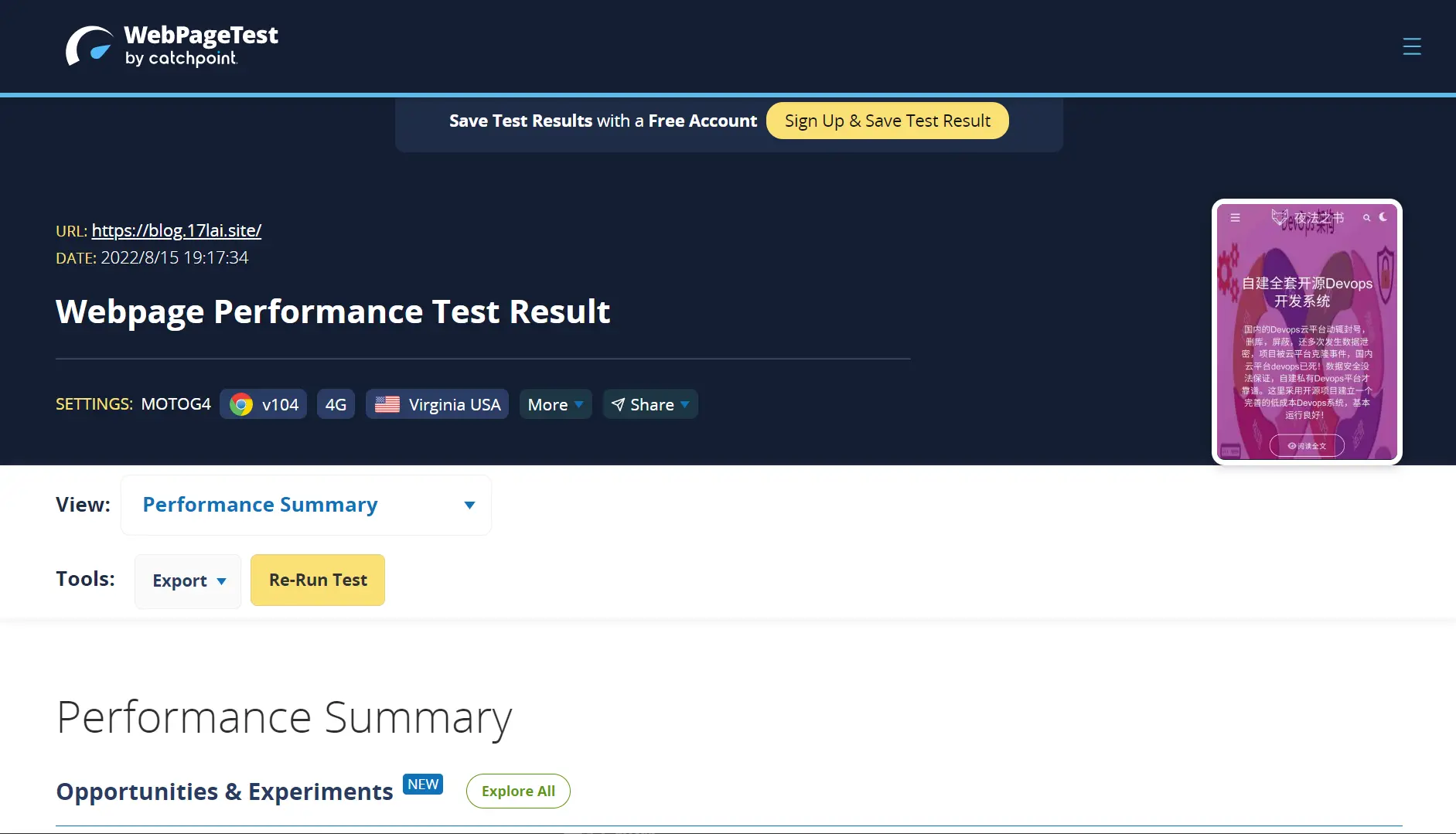
webpagetest是非常强大的测试网站加载速度并深入分析网站资源加载速度的工具,还可以测试网站在不加载(屏蔽)某些资源的情况下网站加载速度与正常加载的对比,这样可以发现让网站加载速度变慢的资源或库。
用户反馈
有时候不同地区的加载速度是不同的,更麻烦的是你很难知道当地的网络情况,这时候就需要用户的反馈了。
加载速度优化概要
图片优化
图片大小优化
优化图片大小非常重要,网站资源大头一般都是图片,图片太大会导致加载速度很慢,在手机端也很耗费用户的流量。一般可以通过对图片大小进行裁剪,对图片格式进行转换这些方式来降低图片大小。
有多种实现方法
<img src="original.jpg"
srcset="thumbnail.jpg"
data-srcset="original.jpg">虽然 <img>标签定义了 src属性,但是由于有 srcset属性,所以现代浏览器会优先使用 srcset的属性加载缩略图 thumbnail.jpg (如果愿意,你也可以使用空白小图 blank.gif)。同时负责 lazyload的 JS 会在页面滚动的时候将 data-srcset属性赋值给 srcset 展示原图。而在不支持 srcset的老旧浏览器或者 RSS阅读器上srcset属性都会被忽略、直接读取 src加载图片。
使用 srcset属性的好处还有更多,比如对响应式设计友好、支持 WebP图片及其 Fallback、对那些 curl 爬虫也很友好。 srcset这个属性的关键之处在于它的优先级比 src属性要高,这就是为什么我们可以在不对 src属性动刀的前提下还可以做到不立刻加载原图。
另一个实现方法 hexo-filter-lqip
图片懒加载
例如这个插件,hexo-lazyload-image,可以极大提高首次显示时间
前端资源优化
网站的前端资源越来越大了,尤其是当你使用了很多第三方库的时候。
用库一时爽,优化火葬场!
如果想极大的提高网站加载速度,尽可能使用少的第三方库。
JS和CSS优化
通过压缩,去除不需要的代码减小前端资源文件大小。
第三方库优化
在这篇《Loading Third-Party JavaScript》中提到了如何正确加载第三方包,通过分析第三方包的加载时序图来判断对加载速度影响最大的几个因素,从而帮助你优化第三方包的加载。
内容结构优化
加载更多
一般对于瀑布流布局的网站,通过加载更多来降低每页返回的页面大小。不过这种方式对爬虫并不算友好,只有第一个页面可以被爬取到。
分页
常规网站一般通过分页来控制每页返回的页面大小。分页页面通过设置唯一的 canonical url 可以让爬虫更好的爬取到分页页面。
CDN
本站使用了免费的 netlify 作为CDN来提高网站在不同地区的加载速度,CDN通过边缘服务器缓存来提高用户请求网页的速度,一般的CDN都会设置某个失效时间后自动去源站拉取最新的内容缓存到边缘服务器。
你也可以选择诸如 Amazon CloudFront 与 cloudflare 这类CDN。还有一些特殊的比如具备反爬虫的CDN,如imperva收购的 distilnetworks 就是很厉害的反爬虫CDN。
静态化技术
动态网站一般需要做一些查询数据库和页面渲染的额外工作,为了提高网站响应速度,一些框架可以自动生成静态化页面部署到CDN中来提高网站响应速度。比如本站使用了基于 Hugo 的静态化技术框架,类似的还有 Hexo,这类技术都属于 JAMSTACK,还有新型的 gatsbyjs 技术让我们更容易开发出更快的网站。
AMP
AMP是Google推出的Web组件框架,可以加速移动端的访问速度,比如你可以看看本篇文章的AMP版本页面,在移动端访问速度是非常快的。
广告优化
使用webpagetest研究本站前端资源的加载速度,最终发现让网站变慢的是Google Adsense广告资源。
通过将广告延迟5秒展示加载的方式来提高页面访问速度,具体代码见 seo improve by delay google ads load,此举将网站加载速度评分提升至90+了。但是测试后发现这种延迟广告展示的方式会降低广告收入😂。
总结
在SEO技术性优化中,提升加载速度是很重要的一个方面,我们需要使用多种手段去降低页面返回的大小来提升网站的加载速度。而且在设计、开发与运营网站的全流程中,加载速度始终是各个环节都需要考虑的问题。
加速NPM安装下载
安装淘宝镜像
npm config set registry https://registry.npm.taobao.org安装CNPM
npm install -g cnpm --registry=https://registry.npm.taobao.org测试您的网络状况
DNS优化
- 多节点部署,多线路DNS配置
- 少用cname
- 双上联负载均衡
CDN 加速
- 为什么强烈建议启用CDN?
研究表明,用户最满意的打开网页时间,是在 2 秒以下。用户能够忍受的最长等待时间在 6~8 秒之间。就是说,8 秒是一个临界值,如果你的网站打开速度在 8 秒以上,那么你将失去大部分用户。研究显示,如果等待 12 秒以后,网页还是没有载入,那么 99% 以上的用户会选择关闭网页。
Google 做过一个试验,10 条搜索结果的页面载入时间需要 0.4 秒,显示 30 条搜索结果的页面载入时间需要 0.9 秒,结果后者使得 Google 总的流量和收入减少了 20%。Google 地图上线的时候,首页大小有 100KB,后来下降到 70~80KB。结果,流量在第一个星期上升了 10%,接下来的 3 个星期又再上升了 25%。Amazon 的统计也显示了相近的结果,首页打开时间每增加 100 毫秒,网站销售量会减少 1%。
以上数据说明了一个非常重要的问题,如果你的网站速度如果超过 2s 以上,那么你的客户可能在流失和离你而去了。这一点对于电商网站尤其重要,打开速度慢,那么将造成转化率降低,损失将会大量增加。
放在 Github 的资源在国内加载速度比较慢,因此需要使用 CDN 加速来优化网站打开速度,jsDelivr + Github 便是免费且好用的 CDN,非常适合博客网站使用。也可以选择主流云服务商提供的对象存储+CDN 来获得更快速及稳定的访问效果,费用低到几乎可忽略。
用法:
https://cdn.jsdelivr.net/gh/{你的用户名}/{你的仓库名}@{发布的版本号}/{文件路径}例如:
https://cdn.jsdelivr.net/gh/appotry/cloudimg@latest/data/2022/03/1120220311110247.webp注意:版本号不是必需的,是为了区分新旧资源,如果不使用版本号,将会直接引用最新资源。
还可以配合 PicGo图床上传工具的自定义域名前缀来上传图片,使用极其方便。具体使用方法可参见这篇文章: 使用 Typora+iPic/PicGo 图床+CDN 实现高效 Markdown 创作
jsdelivr
jsdelivr 是还在目前还在国内运营的可以通过特殊方法免费使用的CDN。
Github开源仓库发布版本才能使用jsdelivr,懂了怎么做了吧。
https://cdn.jsdelivr.net/gh/[name]/[repo]@latest/data/2022/03/1120220311110247.webpCloudflare CDN
配置最简单的CDN方式了。在github raw链接地址前面加
https://images.weserv.nl/?url=, 就会自动使用cloudflare cdn来加速图片访问。使用发现无法加速gif。
本blog主要使用这个方法,如下所示。
- 未加速图片地址
https://raw.githubusercontent.com/appotry/cloudimg/main/data/2021/09/1020210910231815.png- Cloudflare加速图片地址
# 使用了cloudflare partner 加速
https://cimg1.17lai.site/data/2021/09/1020210910231815.png配置Service worker
后篇文章基于Hexo的matery主题搭建博客个性定制篇5中提到的 让hexo支持pwa 就是使用的
Service worker,参考个性定制篇,把常用的大体积文件加入Service worker缓存列表,可以极大的提高访问速度!原理:在访问时,后台异步加载 SW 缓存文件列表,后面渲染网页,直接使用缓存中的文件,不再从网络中获取。你可以提前把所有常用的大体积资源放到缓存列表中,后面访问其它页面时,很多资源已经提前加载好了,可以极大的提高访问速度!
SEO 优化
搜索引擎优化,又称为 SEO,即 Search Engine Optimization,它是一种通过分析搜索引擎的排名规律,了解各种搜索引擎怎样进行搜索、怎样抓取互联网页面、怎样确定特定关键词的搜索结果排名的技术。Google 自动收录效果还不错,百度就差得远了(
GitHub不允许百度的Spider爬取GitHub上的内容)。如果没有备案,百度seo是不会收录的!所以如果你有国内vps,并且备案了,可以做百度seo,如果没有,百度seo内容都不需要看了。
网域提交方式
自动提交
(分三种)
- 主动推送
- 自动推送
- sitemap(站点地图)
手动提交
- 即手动地将链接一次性提交给百度
一般自动提交比手动提交效果好一点,自动提交又从效率上来说:
主动推送>自动推送>sitemap
自动提交的三种方式:
主动推送:最为快速的提交方式。将站点当天新产出链接通过此方式推送给百度,以保证新链接可以及时被百度收录。自动推送:最为便捷的提交方式。将自动推送的JS代码部署在站点的每一个页面源代码中,当部署代码的页面在每次被浏览时,链接就会被自动推送给百度。可以与主动推送配合使用。sitemap:您可以定期将网站链接放到sitemap文件中,然后将sitemap文件提交给百度。百度会周期性的抓取检查您提交的sitemap,对其中的链接进行处理,但收录速度慢于主动推送。
使用sitemap方式推送
安装 sitemap 插件生成站点地图文件:
npm install hexo-generator-sitemap --save
npm install hexo-generator-baidu-sitemap --save #百度专用安装后直接执行 hexo cl&&hexo g -d 命令,就会在网站根目录生成 sitemap.xml 及 baidusitemap.xml 文件。
- 在博客目录的_config.yml中添加如下代码
# 通用站点地图
sitemap:
path: sitemap.xml
# 百度站点地图
baidusitemap:
path: baidusitemap.xml百度优化
登录百度搜索资源平台, 登录成功之后在 用户中心 –> 站点管理 页面中点击添加网站,按提示操作。
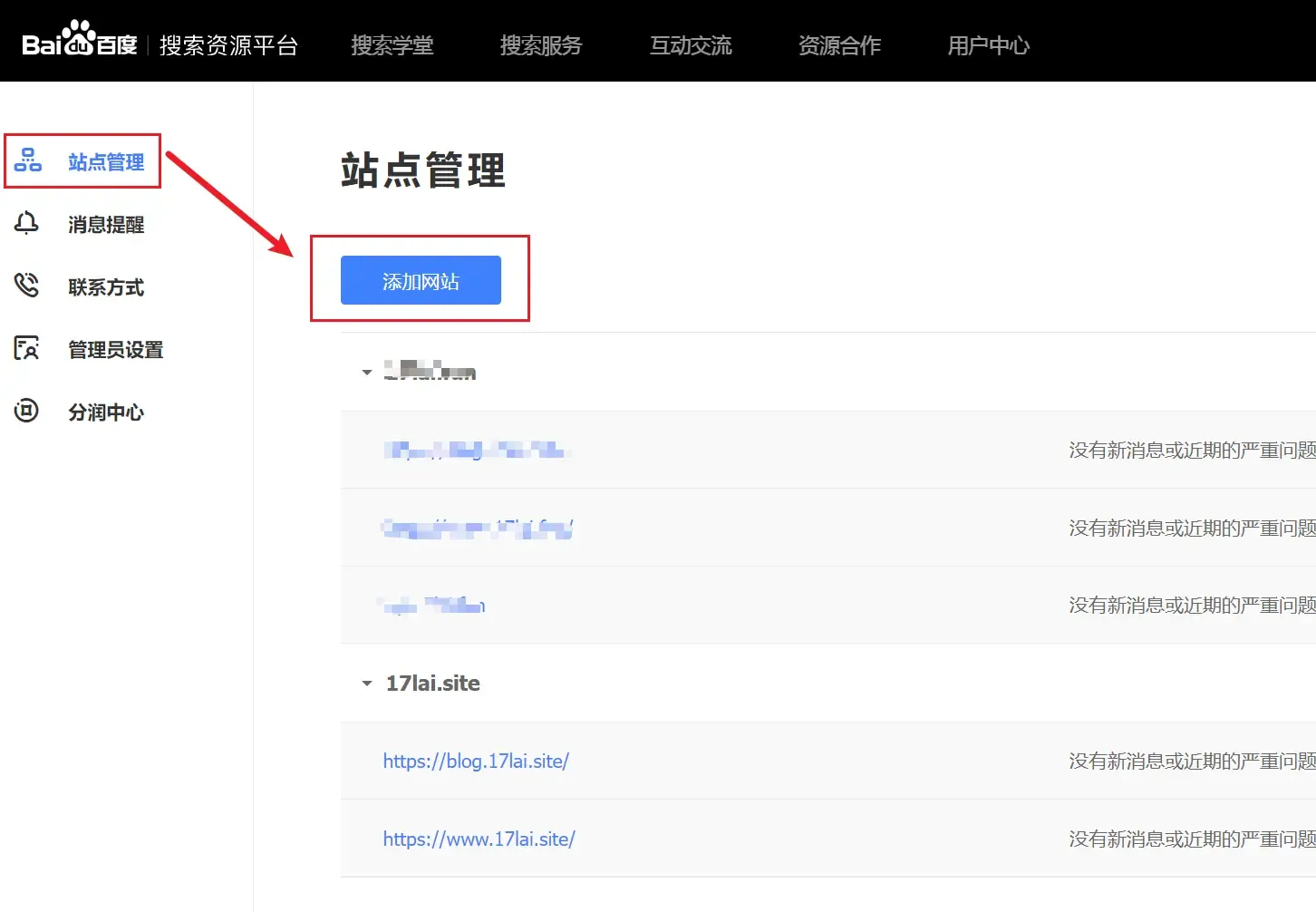
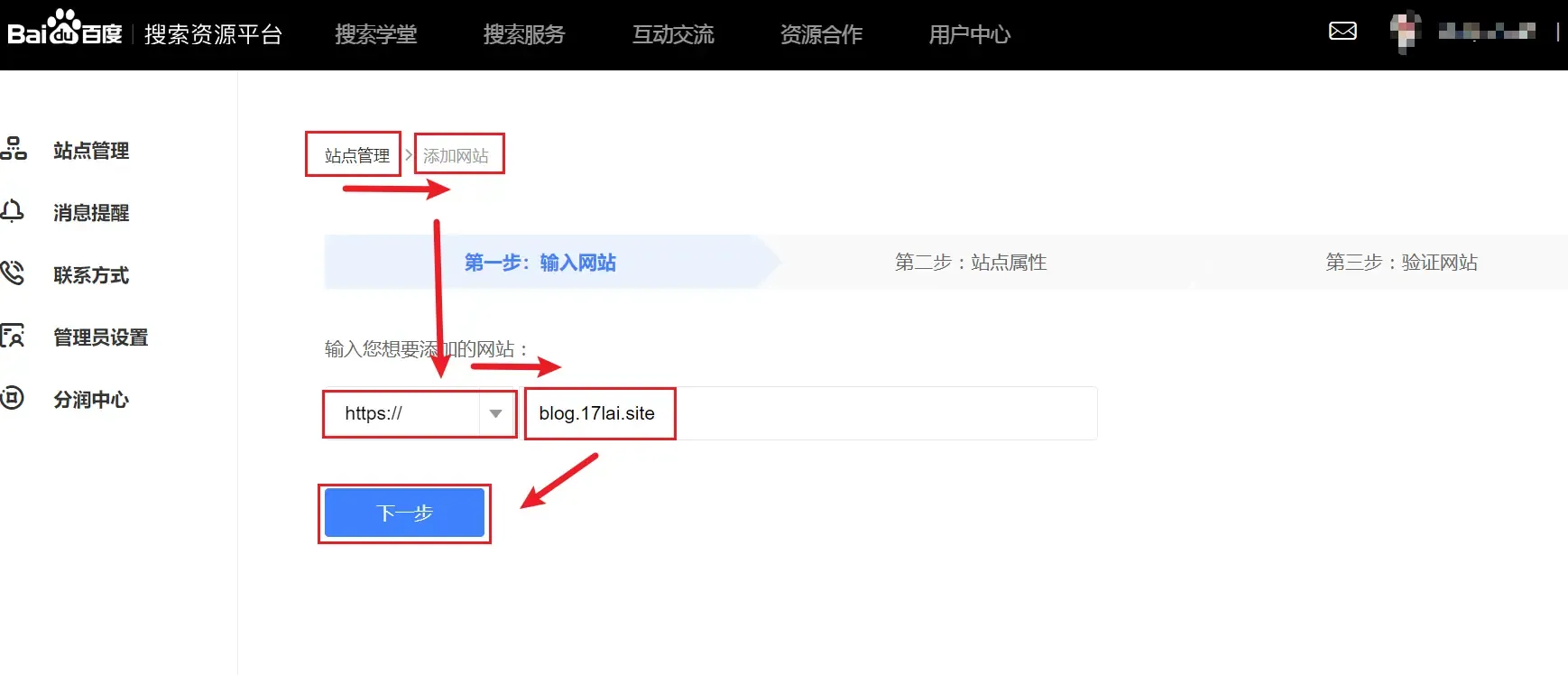
添加网站
提示:由于百度的 spider 是爬取不到 GitHub 的内容的,所以在第三步验证网站的时候,建议选择
CNAME验证的方式。
经过以上步骤,百度已经知道有我们网站的存在了,但是百度还不知道我们的网站上有什么内容,所以要向百度推送我们的内容。点击 网站支持 –> 数据引入 –> 链接提交菜单,提交站点地图:
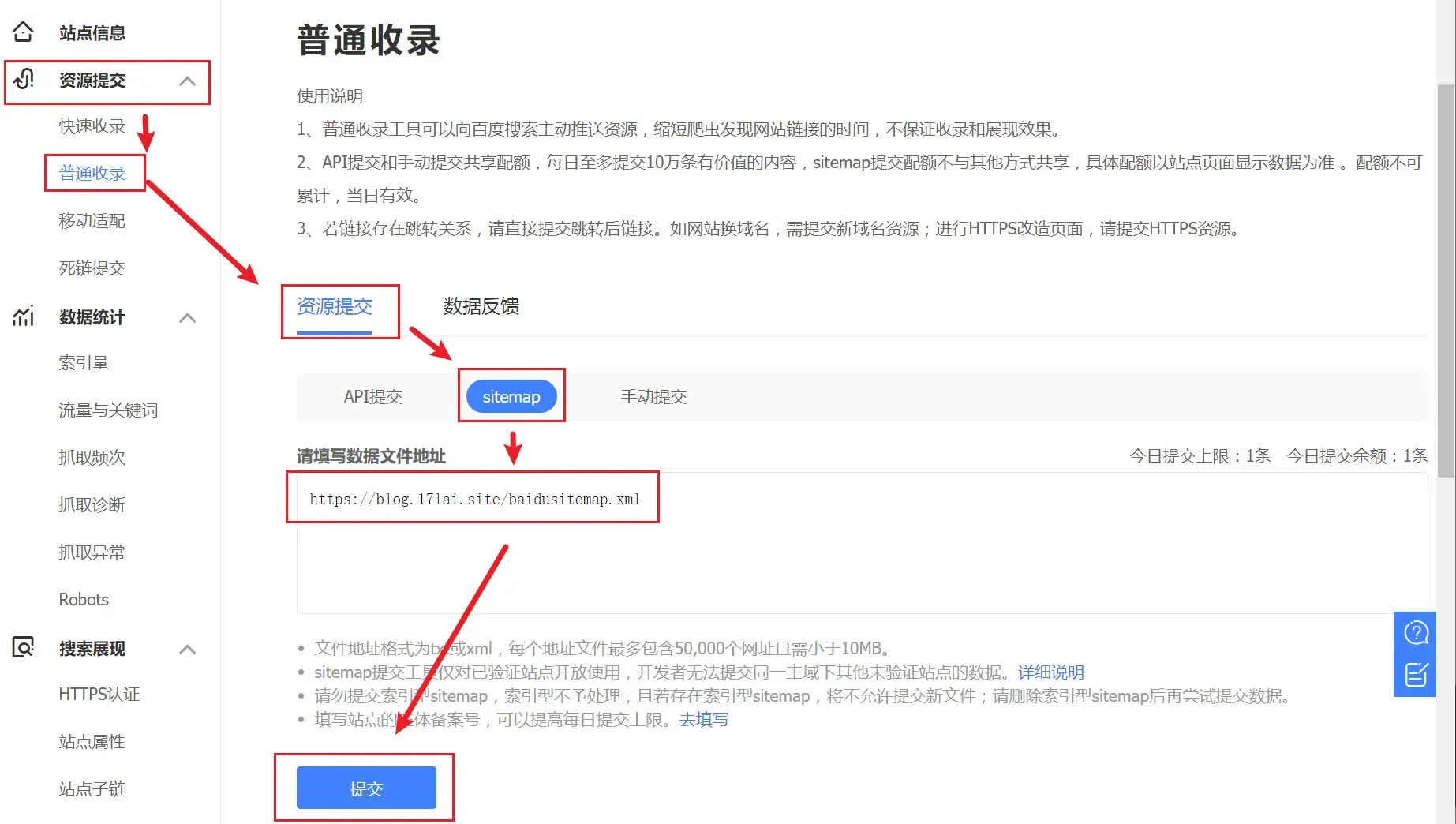
提交站点地图
另外,hexo-theme-matery主题已经内置了 自动推送 的功能, 检查 themes/hexo-theme-matery/_config.yml 文件中如下配置:
# 百度搜索资源平台提交链接
baiduPush: true自动推送的 JS 代码部署在站点的每一个页面源代码中,当页面在每次被浏览时,链接就会被自动推送给百度。
谷歌优化
登录 Google Search Console,点击添加资源,输入自己的域名,按提示操作。
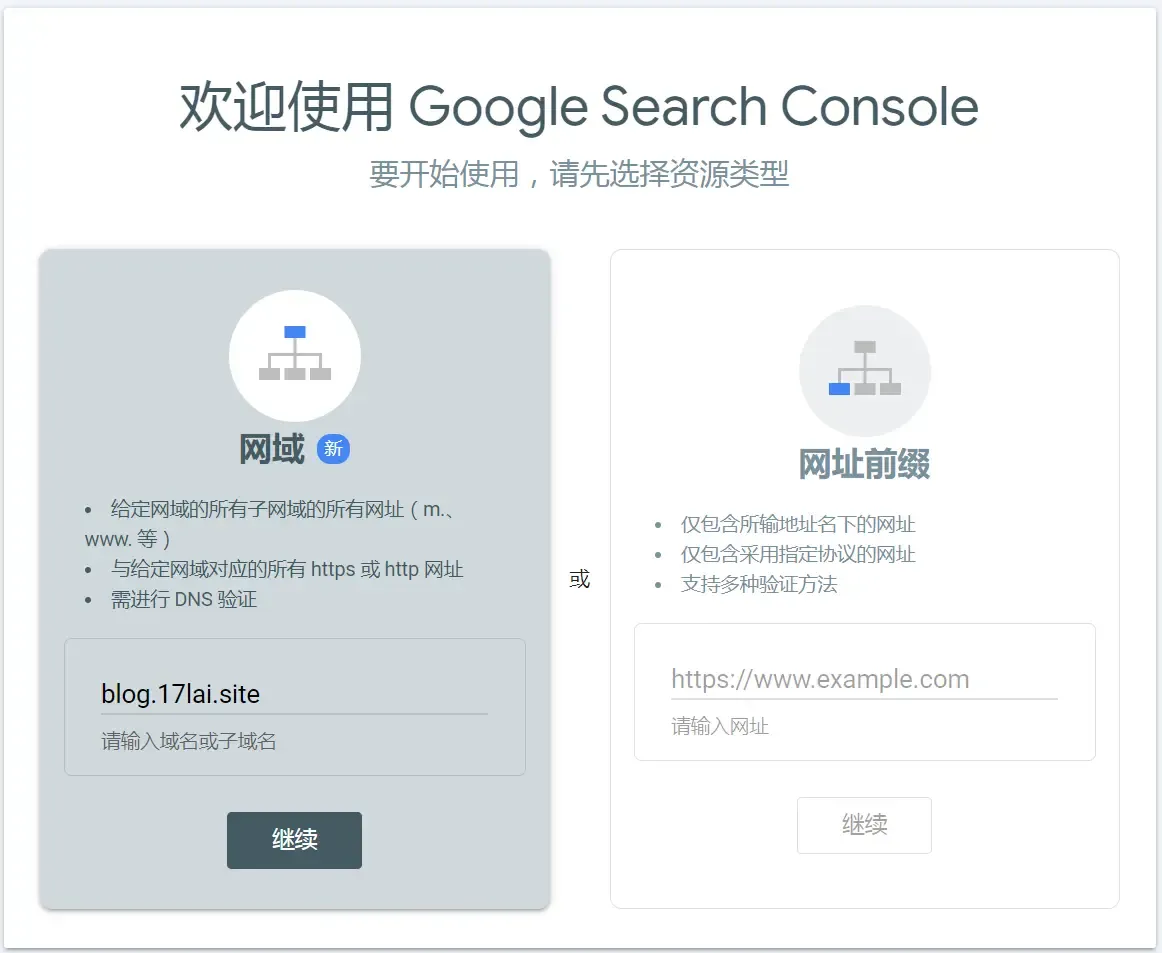
添加资源
提示:需要进行 DNS 验证,进入 DNS 域名解析设置页面,按提示增加 TXT 记录,如下图:
DNS验证内容填写示例

验证成功后,需要提交站点地图。参照下图提交,然后等待收录。
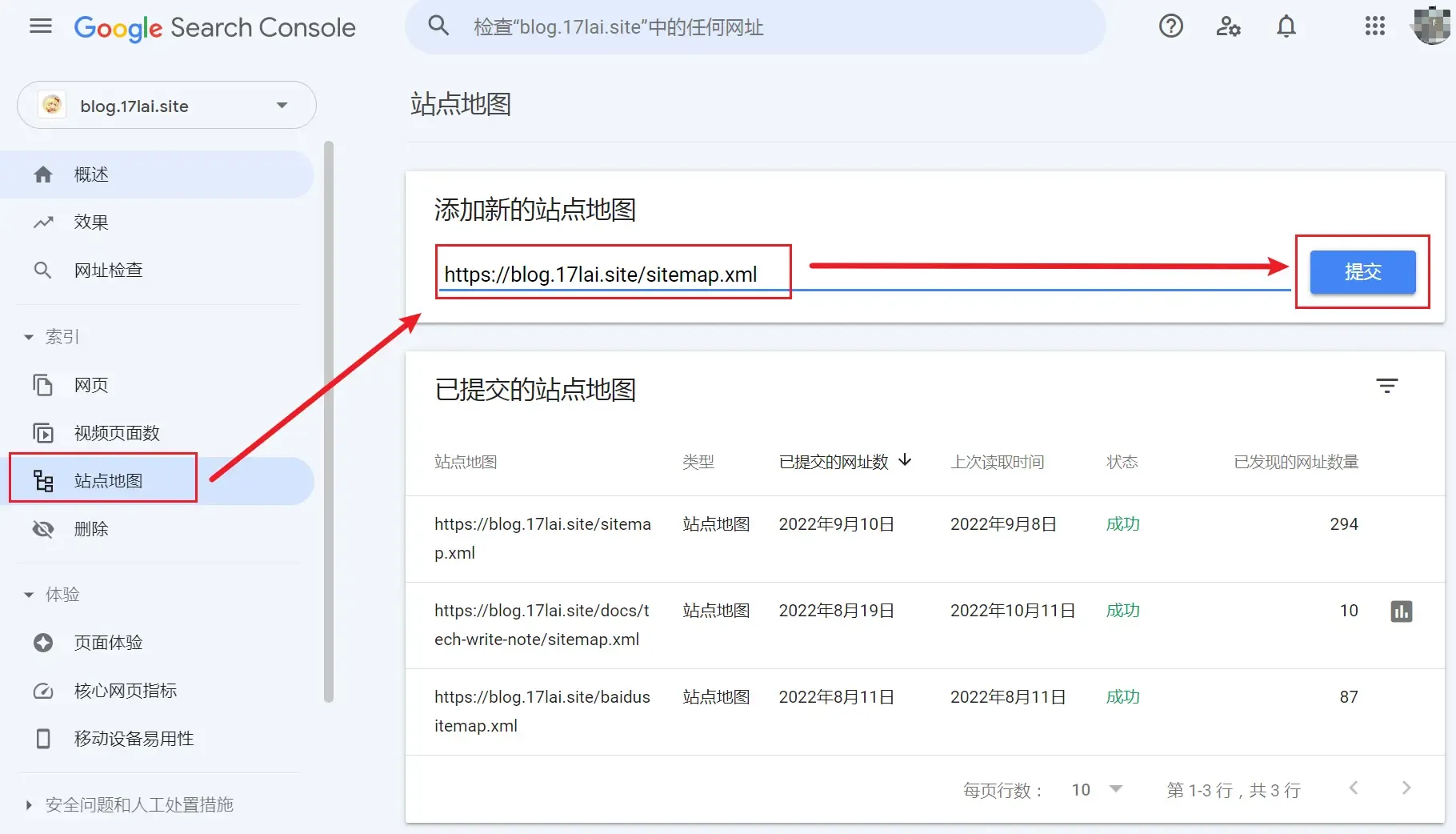
提交站点地图
注意:hexo 配置文件中的 url 一定要输入正确的域名,插件是根据 url 生成站点地图的。
其它搜索引擎
百度自动推送方式
只要每个需要被百度爬取的HTML页面中加入一段JS代码即可:
<script>
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https') {
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else {
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
</script>我所使用的matery主题可以自动给每个页面加上这段代码,只需在主题配置文件中配置:
# 百度搜索资源平台提交链接
baiduPush: true即可!
其他主题一般都有这个功能的实现,如果没有的话,想办法在每个页面加入以上JS代码即可,原理是一样。
百度主动推送SEO方式
- 配置文章自动推送到百度蜘蛛
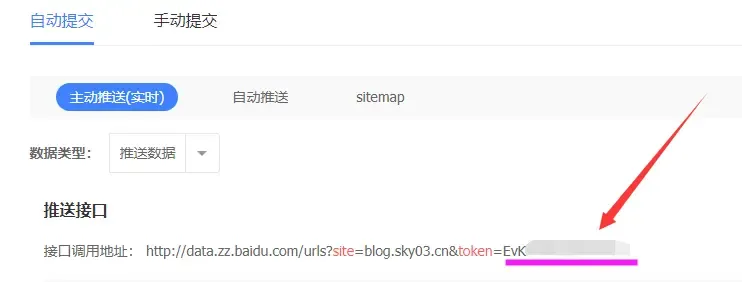
获取百度推送密钥
在 百度资源 注册你的网址,验证完后可在站点管理->资源提交->链接提交->主动推送(实时) 中找到你的推送密钥,下面说明中的 token= 后的内容即为推送密钥。
推送接口
接口调用地址:http://data.zz.baidu.com/urls?site=https://ifibe.com&token=xxxxxxxxxx安装主动推送插件:hexo-baidu-url-submit
$ npm install hexo-baidu-url-submit --save然后打开hexo配置文件,在末尾加入以下配置:
# hexo-baidu-url-submit 百度主动推送
baidu_url_submit:
count: 80 # 提交最新的一个链接
host: https://blog.17lai.site # 在百度站长平台中注册的域名
token: xxxxxxx # 请注意这是您的秘钥, 所以请不要把博客源代码发布在公众仓库里!
path: baidu_urls.txt # 文本文档的地址, 新链接会保存在此文本文档里密匙的获取是在百度的自动提交的主动推送那里。
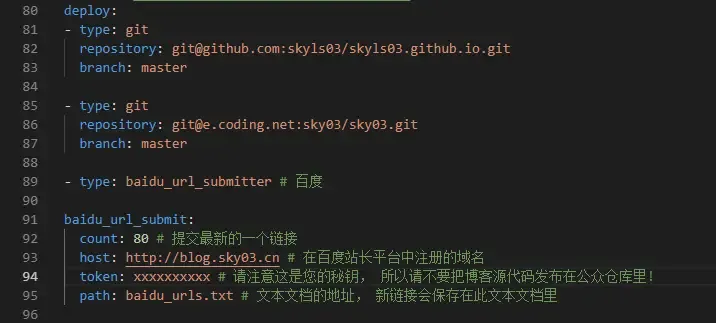
再加入新的deploy:
deploy:
- type: baidu_url_submitter如图:
这样每次执行 hexo d 的时候,新的链接就会被推送了。
$ hexo clean
$ hexo g
$ hexo d推送成功时,会有如下终端提示!
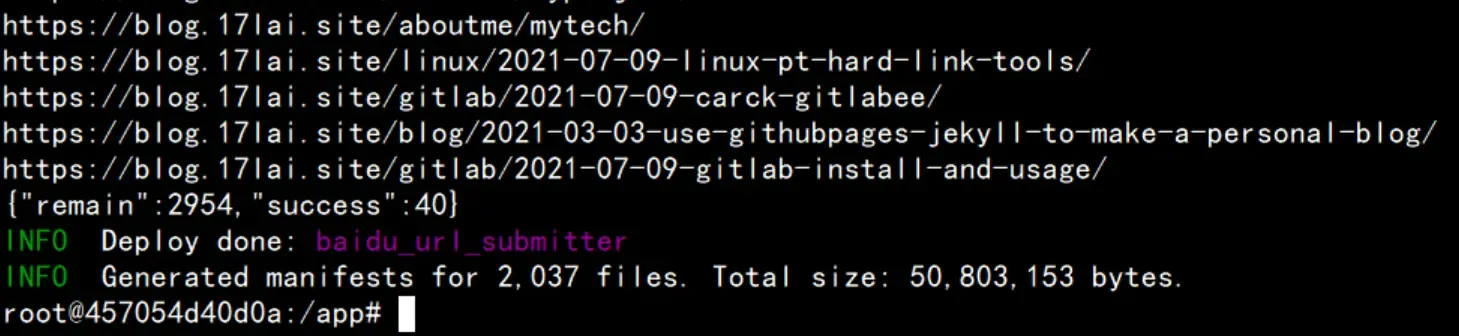
各种不同的推送反馈字段说明点我查看,一般来说,推送失败基本都是地址不相符造成的,我们只需对比baidu_url_submit在public中生成的baidu_urls.txt的地址,与自己填写在host字段中的地址对比看是否一样即可。
Github Action 自动提交SEO方式
强烈推荐使用!Hexo-SEO-AutoPush
安装插件
npm i hexo-seo-autopush --save配置
在hexo 的config.yml里添加
hexo-seo-autopush配置
# enable: 开启/关闭 推送
# count: 每次提交最新的10篇文章
# https://github.com/lete114/hexo-seo-autopush
hexo_seo_autopush:
baidu:
enable: true
count: 100
bing:
enable: true
count: 10
google:
enable: true
count: 10
google_file: google_service_account.json # 谷歌服务账户添加Google Push配置和解决push后没有GitHub Actions .github\workflows\AutoPush.yml文件的问题
# Deployment
## Docs: https://hexo.io/docs/one-command-deployment
deploy:
- type: git
repo: https://github.com/lete114/Test.git
branch: main
ignore_hidden: false # 忽略隐藏文件及文件夹(目录)
- type: GooglePush # 谷歌提交获取站长平台密钥
Baidu Key
- 打开百度站长平台,点击左侧的普通收录https://ziyuan.baidu.com/
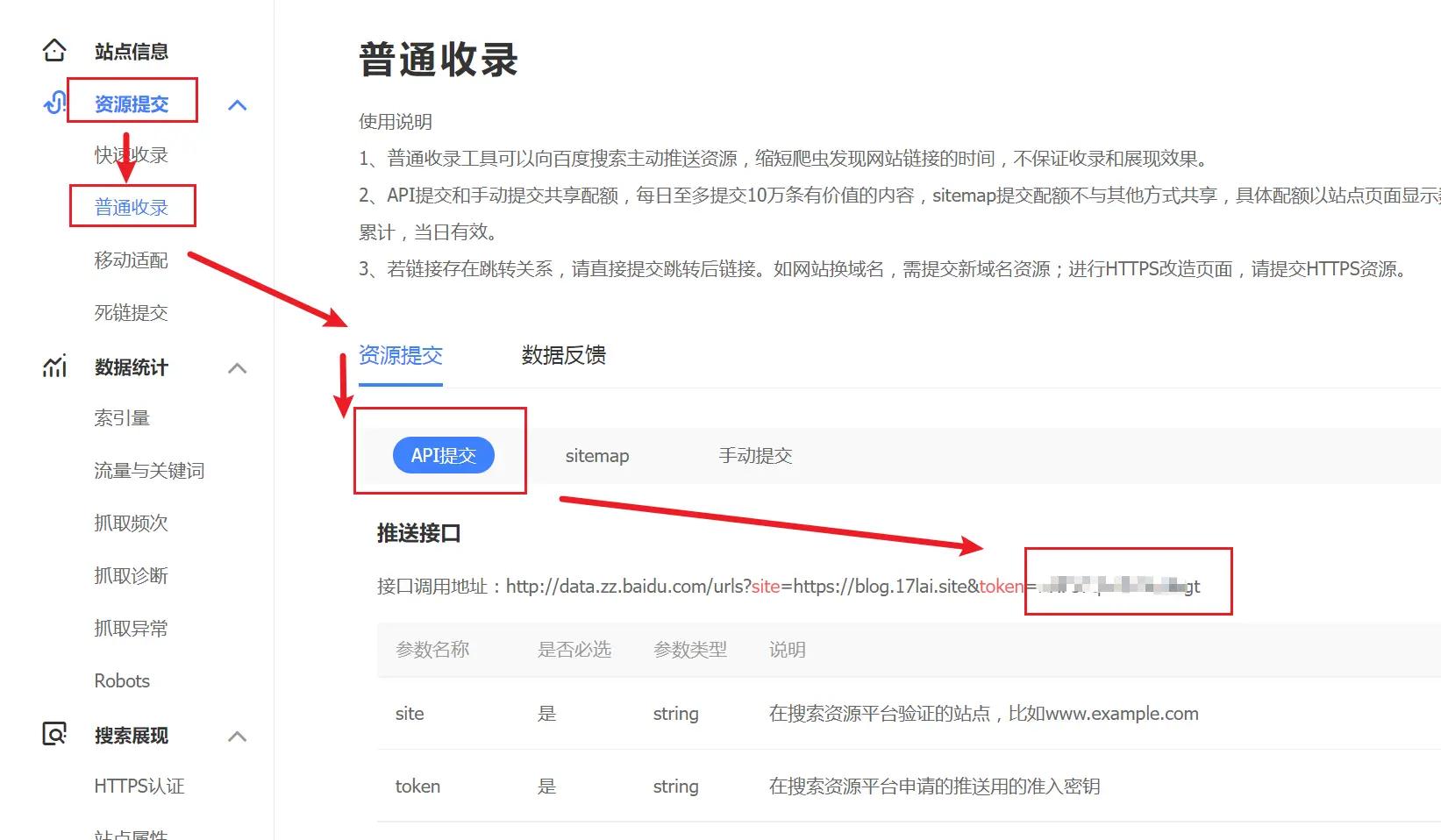
Bing Key
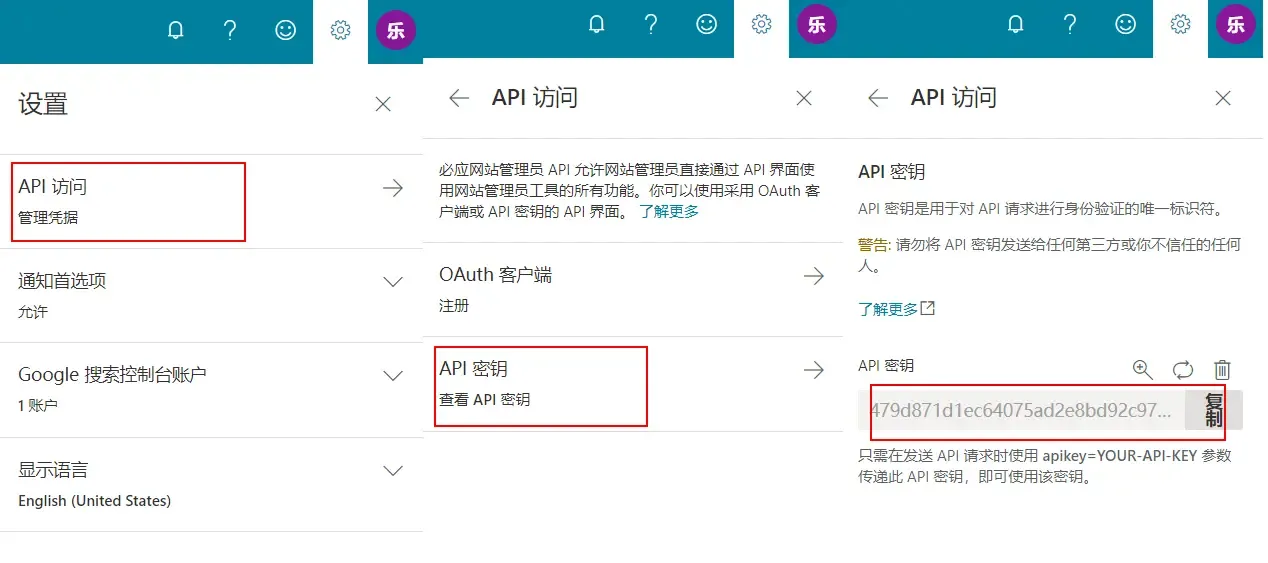
- 打开Bing站长平台,https://www.bing.com/webmasters/home
- 点击右上角头像 旁边的齿轮,跟着下图操作
Google Key
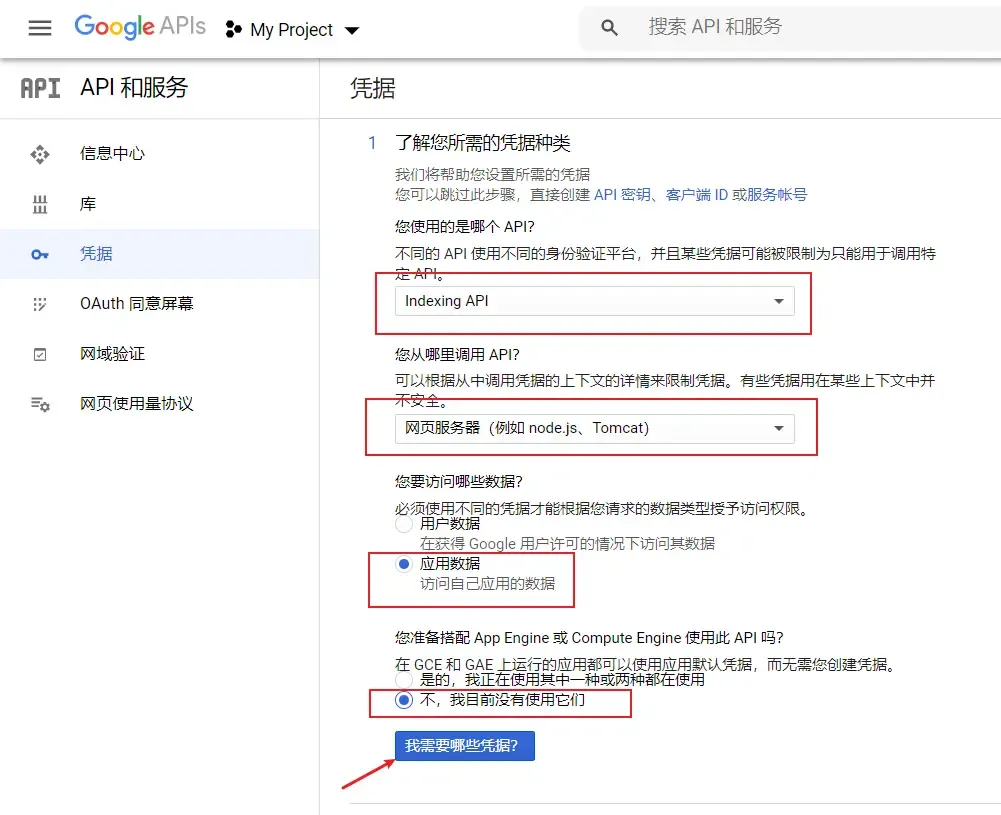
Google Wiki, 使用参考。
打开Google indexing API官网
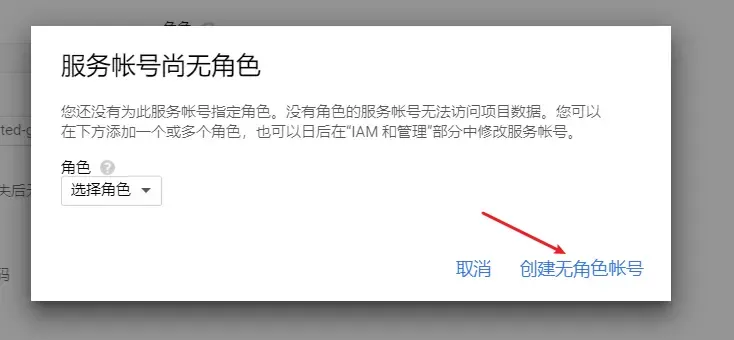
选择创建项目,点击继续
点击转到凭据页面
跟着如下图片步骤
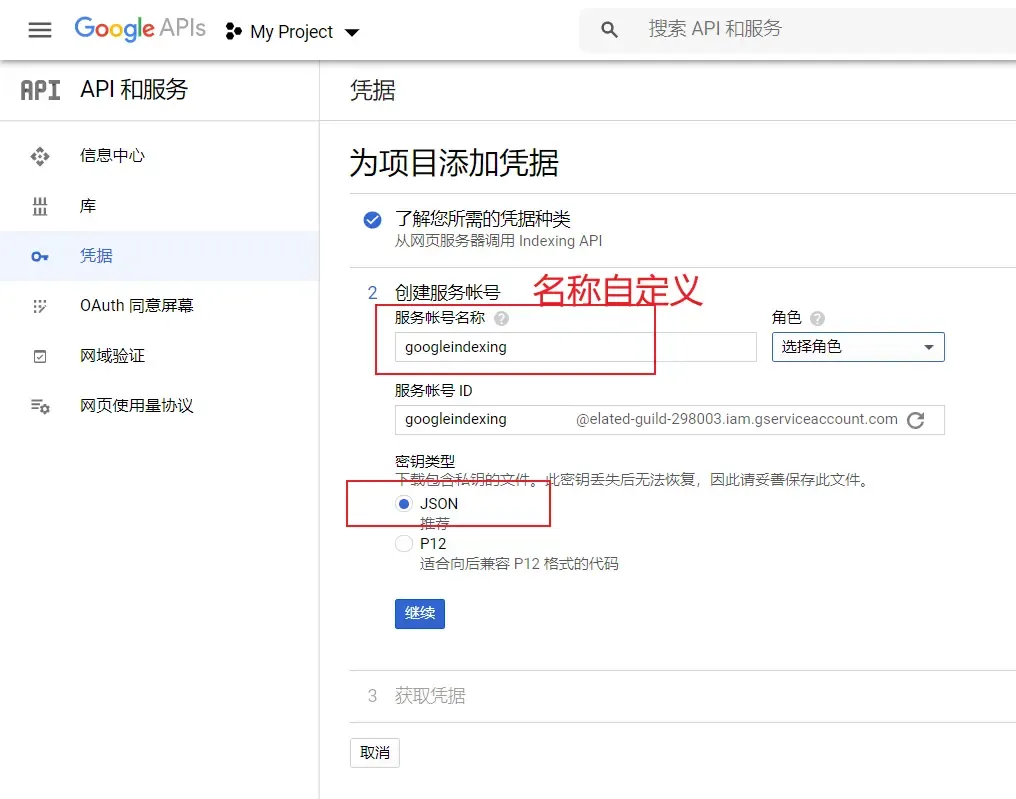
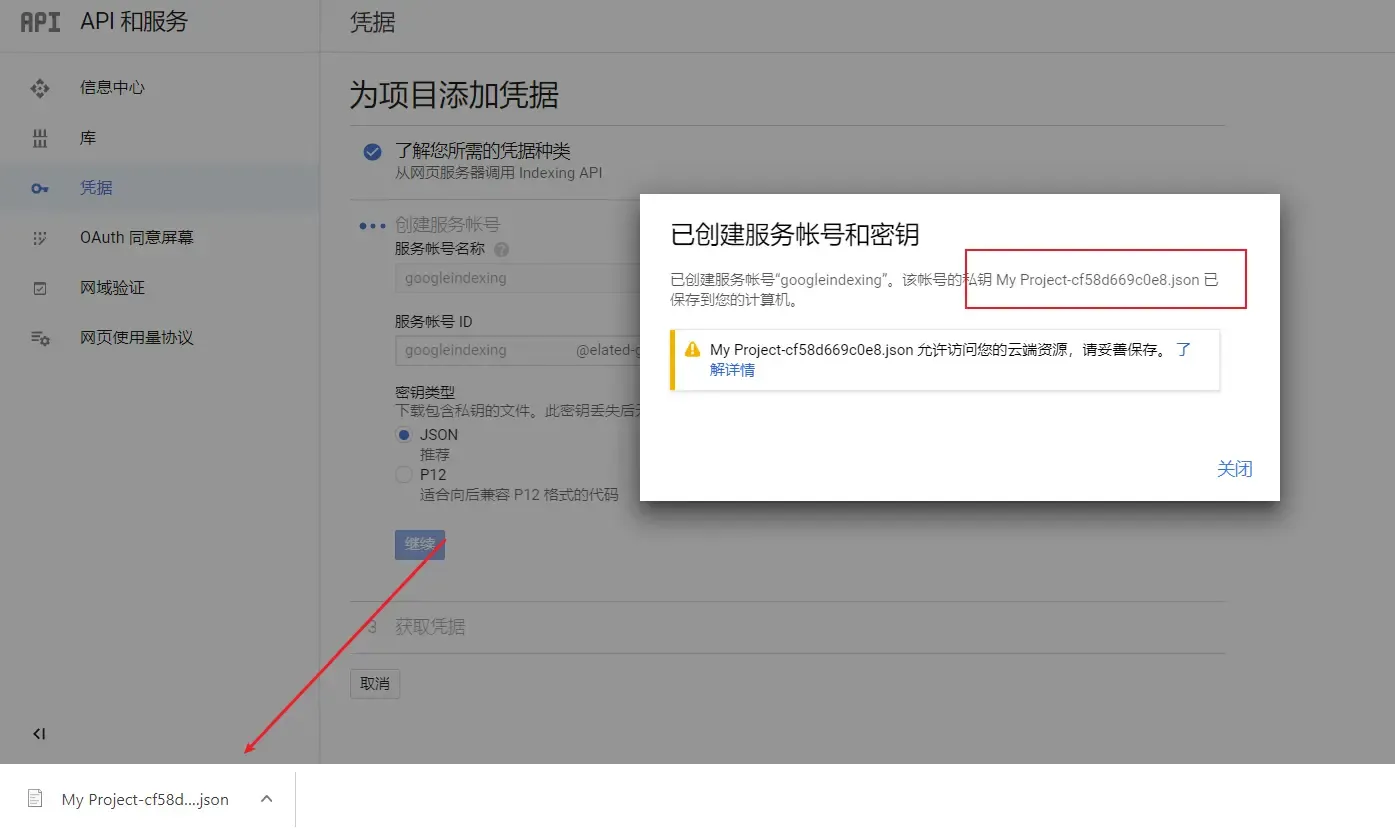
json文件内的内容
{ "type": "service_account", "project_id": "elated-guild-298003", "private_key_id": "cf58d669c0e8c8e082b2c403ade5e2548078e384", "private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvgIBADANBgkqhkiG9w0BAQEFAASCBKgwggSkAgEAAoIBAQDEAJw89yeylRrA\nB+bzOAfQQNgOCABIwEKCy5mMxWSaiXy2RktyCJWjMR2Pgz770NJgClQHPJjsFn0c\nukHufpnuiX3VPlimLANPCRFdU/qp+yiaw4quIhYF1UZJkhmhL30anghUcvi+r9hQ\nw+RwcKrgA4EUzqUJaPdvjtzSoo315PPGfR91ASD5S8gE02yVI8igtYMX7v2x1JYR\n7PwHJwOVemiM9lot8ilvoUbV4BU0vSlwFoxKMJAbEXTmJjEKQi9992rcMW0GzXO8\ncHldUUtURXkt3VFjYTH27KhHiTkTXw+uZRBu1rkubDJkS8lGIWN7Fc/r4HMMCVTu\nXPS6HbJ/AgMBAAECggEANSS7OBaFd3jRL3cVCiZLjA5A5pEJzq/+eKtOn2oYDISx\nwVRO+YTVWdGj47kg1zM4D11NikbGaeDxHFxuKwW9o/04lpyYebneTcw2Hpl6EiOs\nz0WssOlCEmPQ8nrAI0GWiKSHuqoPwtg37TIoGsqZsjKRCby759DDokZYnm3/0sc+\niEllT0ZyBZhGDzyguVLEdCIR2P02q/hQzLyd6ejWGGwZebImbGoILhmuOjVrco0p\nV0JbrrNskjM5Epe7w+CpGftEASJ7Dxa8oj0qIT6cyAipra2AZAGnG9jrLcWpJuhu\nvNeDIFnTfpNEac+khXZZE2++MIQfTX9wGJc8tox2vQKBgQD6yiNvAL7sxExiy6ER\ntLtFQ3bvmMpKRFGvFOyPOtMbmjZ3D1GEtNNKGH4v1TI+tncEy7Q5Dm7nWwpi8yvL\nbh8xKghelAc/CU1nw0xDEDCkMbAwpFg5A5ZDImy3LZsQh0kNXniIMy1vMSt5yLKS\n80gXQKGCxG8t3rP8Qd/2a55g1QKBgQDIExP1nG9sHJaigmitEUwr0Ow6Shqr56Me\nd7995gaV1oLWWCQzrXt/viWkb1W5ZGIxzcWNWz99m4CbvqfewRr598Eenald0csN\nVcIEk+0C+6KqA+jU9Tfs2zow/C7JuKULP2N++o0EoSz/ngokP7f1yLOYbr507v/R\n0cLElQBQAwKBgAbxDWYHKUG4dTzO0hiBXiWepm4fVooTtgcYlyunvywmapeFDwaT\nUr3cS7HbPtbJiiXR1Z02rw8sT+9JN88brzVXKoAjrMer5D6ZA0Vf71i8H1pZUi/R\nz5jwHP48/uvIMtdx4/gxInLPc5qdWYQDw90Q5ueNtF4aqfSzhhV2CR45AoGBAJN9\nPOF6iMjx6jmyWOf8MGK8iOgPaMoA4Ea9j/SHdaNPlvPb1hQid0AcNDObv14Dmj+M\nqW0jLxKxZ4VobufPAsvyz/J51zjKRx11cqldQwNH7QnYB/O1MZzxn1wtC3C5JTG9\ncONSYFJhXoKxRliigEI3ye089jnNVdifAS1ZiflxAoGBANTX1fEMEeNuYU0v3rtd\n5CkPZg4TNZ+y2MGl5xR1LdIgrJ8c9xKoW4rpp7SsOIvHpWX494f90D7o9uFEGSQ4\nyQK53jVzJ0ekGV5BdPF3n3/2j2VEqFLHi7LL4CJSxr6ci7OfBoHOGE8odhevQCCK\njnFzEin0QsBEgIC73fBh6XcH\n-----END PRIVATE KEY-----\n", "client_email": "googleindexing@elated-guild-298003.iam.gserviceaccount.com", "client_id": "103034240916368863393", "auth_uri": "https://accounts.google.com/o/oauth2/auth", "token_uri": "https://oauth2.googleapis.com/token", "auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs", "client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/googleindexing%40elated-guild-298003.iam.gserviceaccount.com" }打开谷歌站长平台
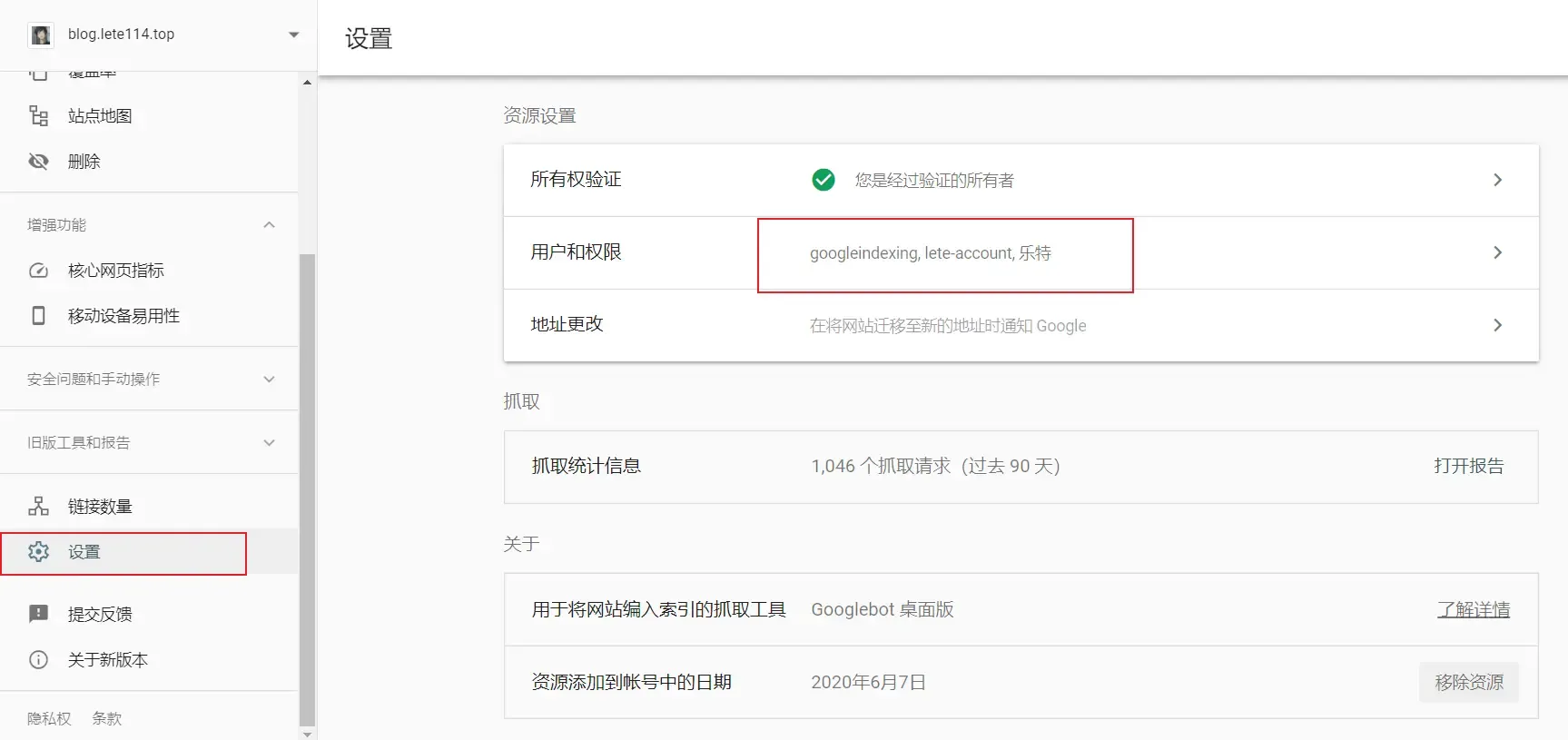
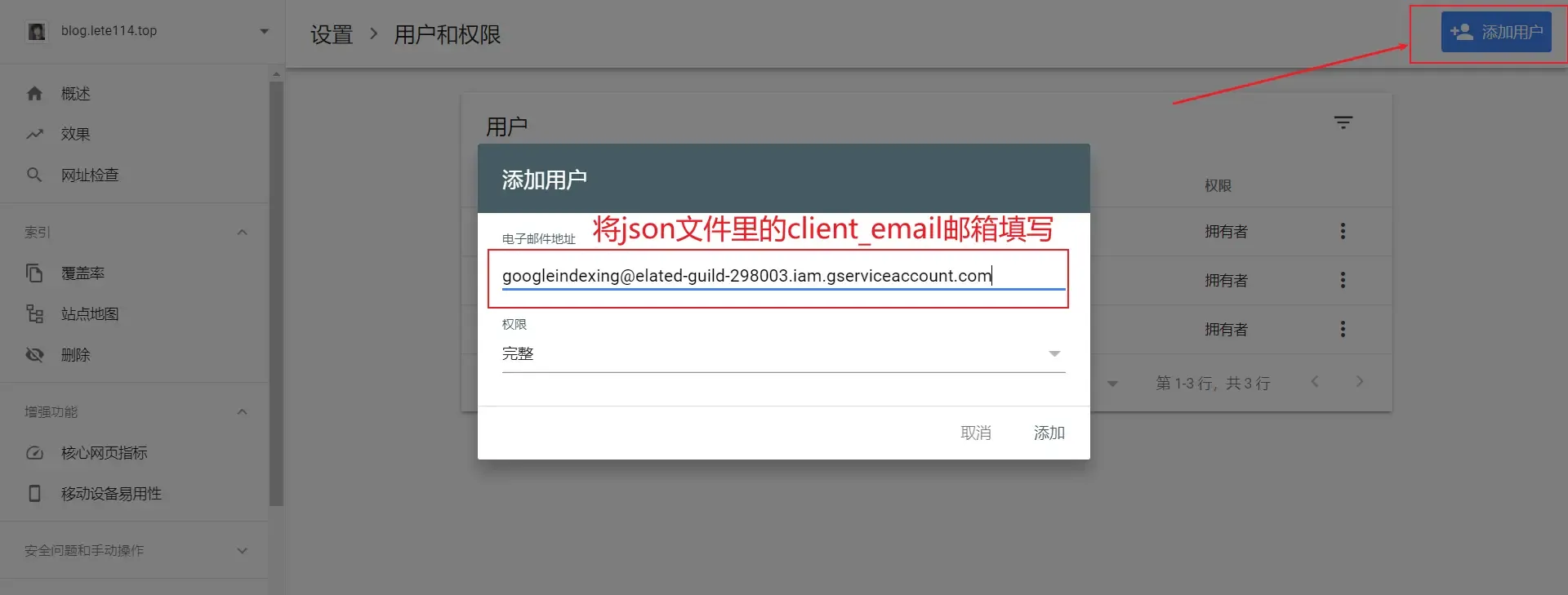
配置博客仓库
Name必须是
baidu_token和bing_apikey(不区分大小写)添加完成后
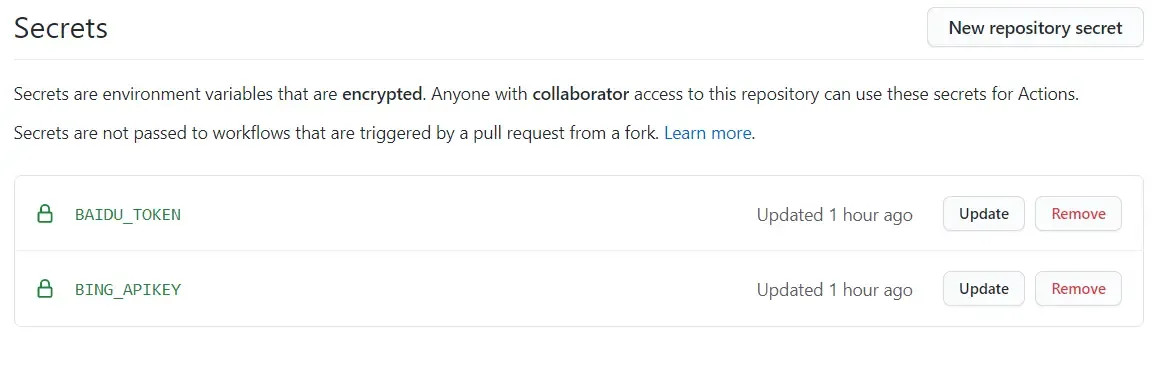
谷歌的一些问题
触发谷歌提交的命令是hexo d
由于谷歌需要配合Google indexing API平台提供的json进行提交,而这个json格式不能泄露为防止json泄露只能本地提交,将json放到hexo根目录可自定义重命名(必须对应插件的配置)如果你的使用Github Actions自动部署的话请把仓库设置为私有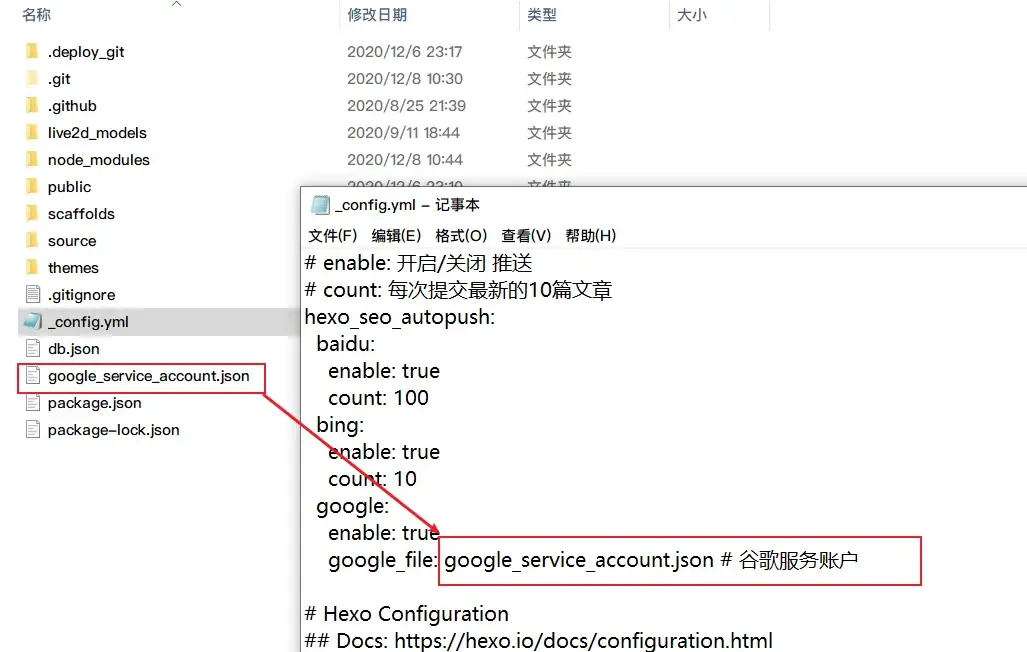
提交成功返回状态码
以上步骤完成后即可hexo d部署了
看看Github仓库是否上传成功
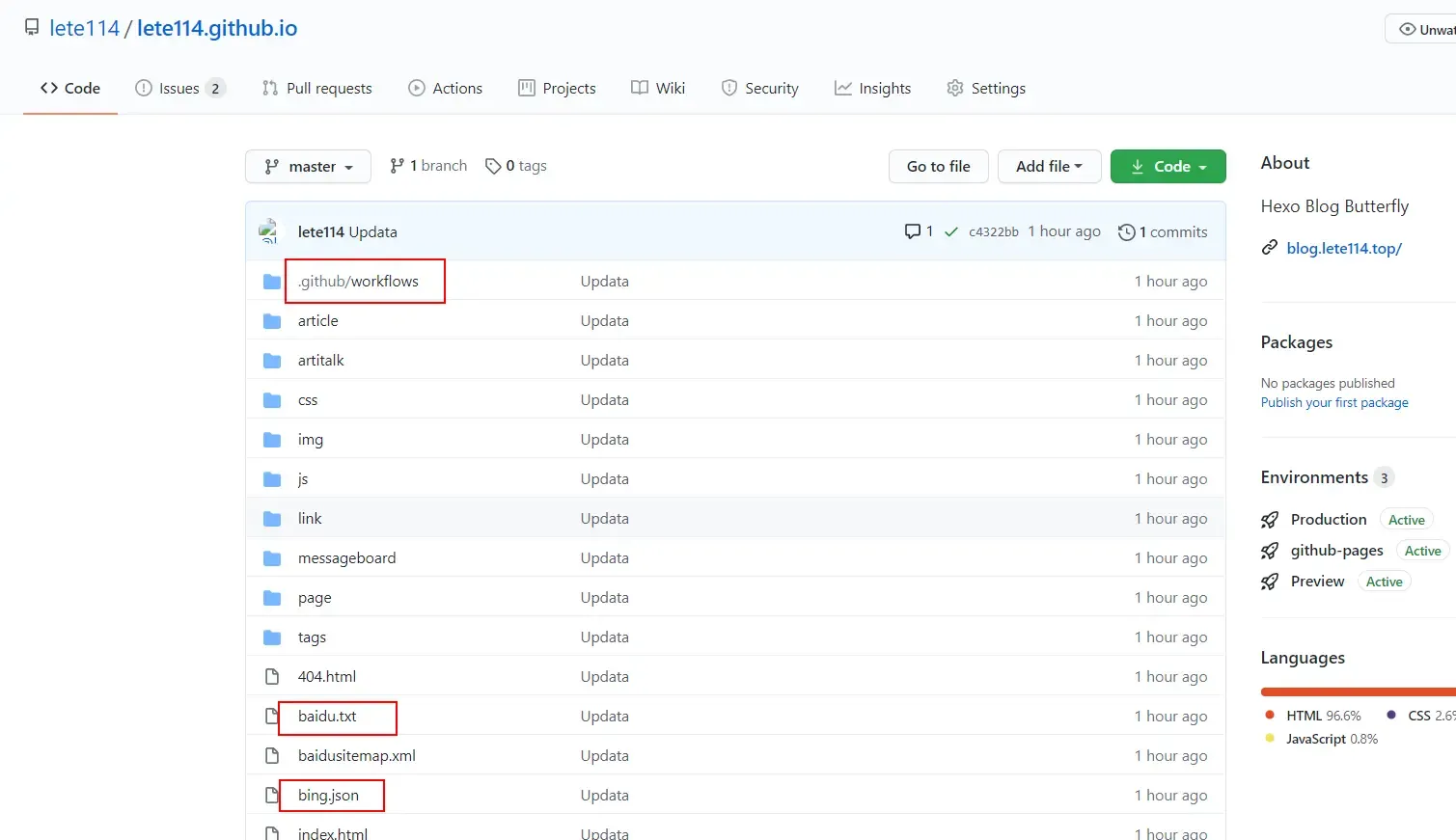
点击
Actions查看是否执行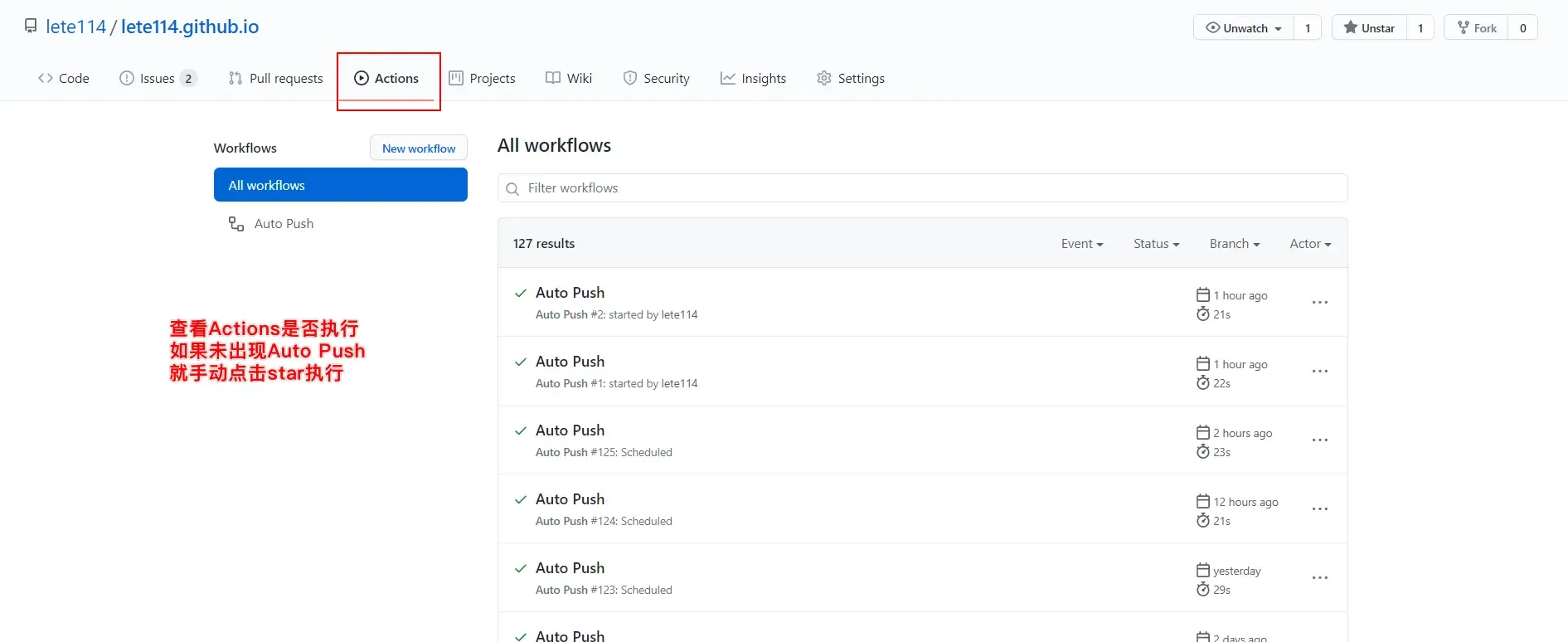
点击 Auto Push—->build—–>点击第2步 自动提交
如图43行
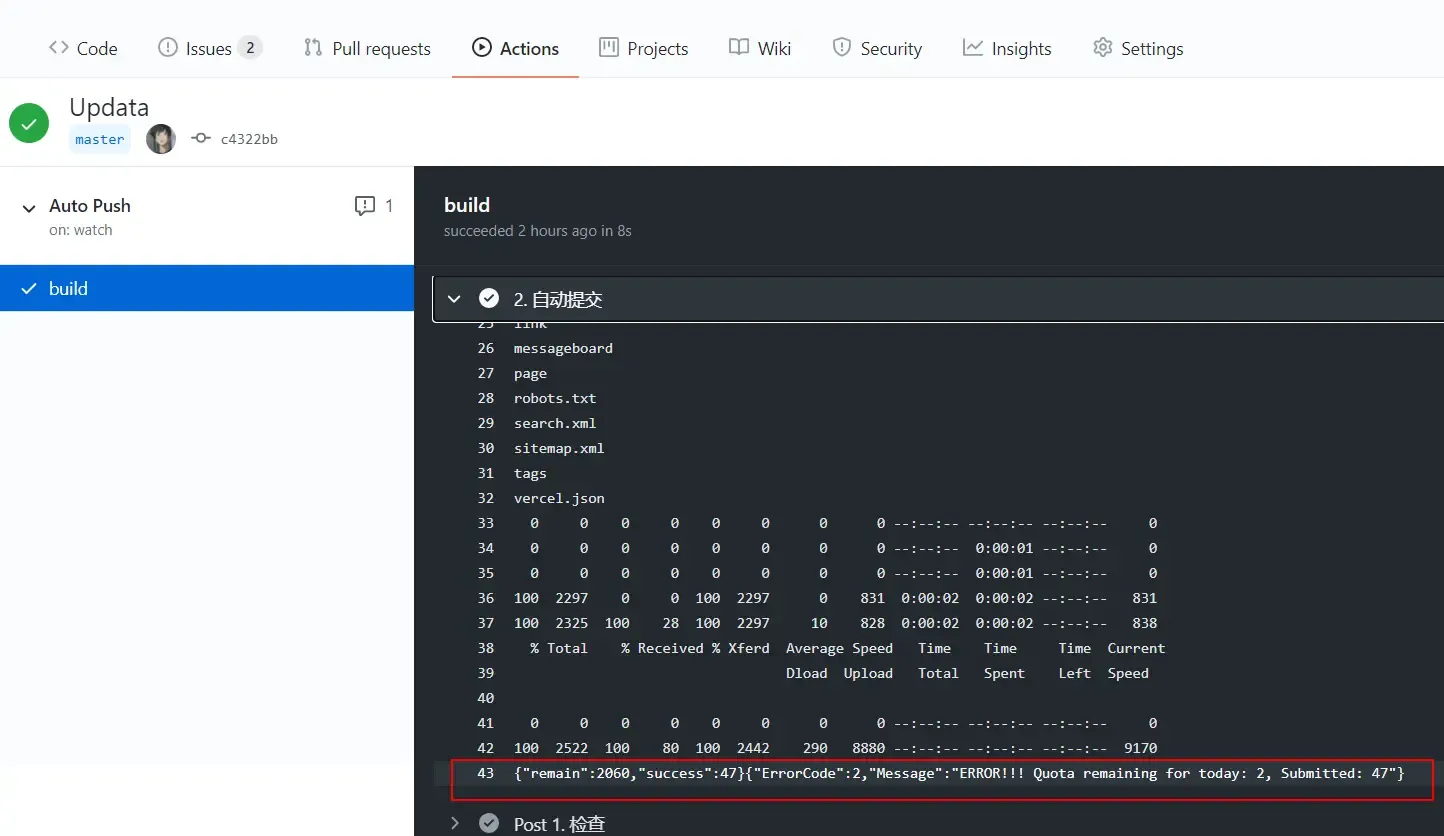
// baidu返回的结果 { "remain": 2060, // 表示当天剩余的可推送url条数 "success": 47 // 成功推送的url条数 } // bing返回结果(错误) { "ErrorCode": 2, // 错误 "Message": "ERROR!!! Quota remaining for today: 2, Submitted: 47" // Message:表示 你目前只剩2个url推送,而你现在推送的是47条url // bing新用户开始每日只有10个推送额,据我了解连续推送10天(这我也不确定) // 如果出现这个错误的话,你就只能先手动添加等系统给你分配额了(分配9999) } // bing返回结果(成功) {"d":null}Google 返回状态码
成功返回
Google response: { urlNotificationMetadata: { url: 'https://blog.lete114.top/article/hexo-seo-autopush.html', latestUpdate: { url: 'https://blog.lete114.top/article/hexo-seo-autopush.html', type: 'URL_UPDATED', notifyTime: '2020-12-08T02:31:32.871417693Z' } } }出现此错误需要: 翻墙
FetchError: request to https://www.googleapis.com/oauth2/v4/token failed, reason: connect ETIMEDOUT 172.217.27.138:443 at ClientRequest.<anonymous> (D:\Lete\GitHub\Hexo-Butterfly\node_modules\node-fetch\lib\index.js:1461:11) at ClientRequest.emit (events.js:321:20) at TLSSocket.socketErrorListener (_http_client.js:426:9) at TLSSocket.emit (events.js:321:20) at emitErrorNT (internal/streams/destroy.js:92:8) at emitErrorAndCloseNT (internal/streams/destroy.js:60:3) at processTicksAndRejections (internal/process/task_queues.js:84:21) { message: 'request to https://www.googleapis.com/oauth2/v4/token failed, reason: connect ETIMEDOUT 172.217.27.138:443', type: 'system', errno: 'ETIMEDOUT', code: 'ETIMEDOUT', config: { method: 'POST', url: 'https://www.googleapis.com/oauth2/v4/token', data: { grant_type: 'urn:ietf:params:oauth:grant-type:jwt-bearer', assertion: 'eyJhbGciOiJSUzI1NiJ9.eyJpc3MiOiJnb29nbGVpbmRleGluZ0BzdGF0ZWx5LXRyYW5zaXQtMjk3NzE1LmlhbS5nc2VydmljZWFjY291bnQuY29tIiwic2NvcGUiOiJodHRwczovL3d3d
本地主动提交SEO
安装方法
- 在终端中输入:
npm i hexo-url-submission- 在
blog/_config.yml文件中添加配置:
url_submission:
enable: true
type: 'latest' # latest or all( latest: modified pages; all: posts & pages)
channel: ['baidu', 'bing', 'google', 'shenma'] # Included channels are `baidu`, `google`, `bing`, `shenma`
prefix: ['/post', '/wiki'] # URL prefix
count: 10 # Submit limit
proxy: '' # Set the proxy used to submit urls to Google
urls_path: 'submit_url.txt' # URL list file path
baidu_token: '' # Baidu private key
bing_token: '' # Bing private key
google_key: '' # Google key path (e.g. `google_key.json` or `data/google_key.json`)
shenma_token: '' # ShenMa private key
shenma_user: '' # Username used when registering
sitemap: '' # Sitemap path(e.g. the url is like this https://abnerwei.com/baidusitemap.xml, you can fill in `baidusitemap.xml`)更新方法
在站点根目录执行:
npm update hexo-url-submissiondeploy
deploy:
- type: us_baidu_deployer
- type: us_bing_deployer
- type: us_google_deployer
- type: us_shenma_deployergood job
Run:
hexo clean && hexo g && hexo denjoy it!
提交 robots.txt
robots.txt是干嘛的?
robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它的作用是告诉搜索引擎此网站中哪些内容是可以被爬取的,哪些是禁止爬取的。robots.txt要放在Hexo根目录下的source文件夹中。
每个人站点目录可能不太一样,可以参考下我的 robots.txt 文件,内容如下:
User-agent: *
Allow: /
Allow: /posts/
Disallow: /about/
Disallow: /archives/
Disallow: /js/
Disallow: /css/
Disallow: /contact/
Disallow: /fonts/
Disallow: /friends/
Disallow: /libs/
Disallow: /medias/
Disallow: /page/
Disallow: /tags/
Disallow: /categories/更多关于 robots.txt 的写法参见 https://blog.csdn.net/fanghua_vip/article/details/79535639
编写完以上内容再重新部署一下,然后到百度资源平台的数据监控->Robots点击检测并更新 看能不能检测到。
配置 Nofollow
- nofollow 是HTML页面中
a标签的 属性值。 - 这个属性的作用是:告诉搜索引擎的爬虫不要追踪该链接,为了对抗博客垃圾留言信息
URL优化
一般来说,SEO搜索引擎优化认为,网站的最佳结构是 用户从首页点击三次就可以到达任何一个页面,但是我们使用Hexo编译的站点结构的URL是:域名/年/月/日/文章标题四层的结构,这样的URL结构很不利于SEO,爬虫就会经常爬不到我们的文章,于是,我们需要优化一下网站文章的URL
方案一:
直接改成域名/文章标题的形式,在Hexo配置文件中修改permalink如下:
# URL
## If your site is put in a subdirectory, set url as 'http://yoursite.com/child' and root as '/child/'
url: https://blog.sky03.cn
root: /
permalink: :title.html
permalink_defaults:这个方式有个不好的地方:
直接以文章的标题作为URL,而我们所写的文章的标题一般都是中文,但是URL只能用字母数字和标点符号表示,所以中文的URL只能被转义成一堆符号,而且还特别长。
方案二:
安装固定链接插件:hexo-abbrlink
插件作用:自动为每篇文章生成一串数字作每篇文章的URI地址。每篇文章的Front-matter中会自动增加一个配置项:abbrlink: xxxxx,该项的值就是当前文章的URI地址。
Hexo根目录执行:
npm install hexo-abbrlink --saveHexo配置文件末尾加入以下配置:# hexo-abbrlink config 、固定文章地址插件 abbrlink: alg: crc16 #算法选项:crc16、crc32,区别见之前的文章,这里默认为crc16丨crc32比crc16复杂一点,长一点 rep: dec #输出进制:十进制和十六进制,默认为10进制。丨dec为十进制,hex为十六进制Hexo配置文件中修改permalink如下:# URL ## If your site is put in a subdirectory, set url as 'http://yoursite.com/child' and root as '/child/' url: https://blog.17lai.site root: / permalink: posts/:abbrlink.html permalink_defaults:
这样站点结构就变成了:域名/posts/xxx.html
Analytics 优化
强烈推荐自建 Umami 统计服务,所有公用的访问统计服务都被浏览器插件拦截工具拦截!
Google Analytics 是一个 gzip 以后都还有 45KB 大小的 analytics.js、Cache-Control 还只有 7200 秒;Google 国内的数据中心会被抽风不说,www.google-analytics.com 域名早就上了各个广告屏蔽软件的黑名单!所以要么自建其它私有统计,要么想办法优化加载了。
Google Analytics 优化 @ WordPress
umami
version: '3'
services:
umami:
image: ghcr.io/umami-software/umami:postgresql-latest
ports:
- "3000:3000"
environment:
DATABASE_URL: postgresql://umami:umami@db:5432/umami
DATABASE_TYPE: postgresql
APP_SECRET: replace-me-with-a-random-string
depends_on:
db:
condition: service_healthy
restart: always
db:
image: postgres:15-alpine
environment:
POSTGRES_DB: umami
POSTGRES_USER: umami
POSTGRES_PASSWORD: umami
volumes:
- umami-db-data:/var/lib/postgresql/data
restart: always
healthcheck:
test: ["CMD-SHELL", "pg_isready -U $${POSTGRES_USER} -d $${POSTGRES_DB}"]
interval: 5s
timeout: 5s
retries: 5
volumes:
umami-db-data:https://github.com/umami-software/umami/blob/master/docker-compose.yml
umami支持MySQL和Postgres,并可以在 Vercel Netlify 上面部署。
Umami UV / PV 统计显示
Umami 统计了 UV PV 等各种访问数据,比不蒜子详细得多,自建服务也比不蒜子稳定。那么怎么用 Umami 代替不蒜子了? 下文将介绍详细方法
新建 View only 权限的用户
Settings` -> `Users` -> `Create user` -> 填写账号密码,`Role` 选择 `View only` -> `Save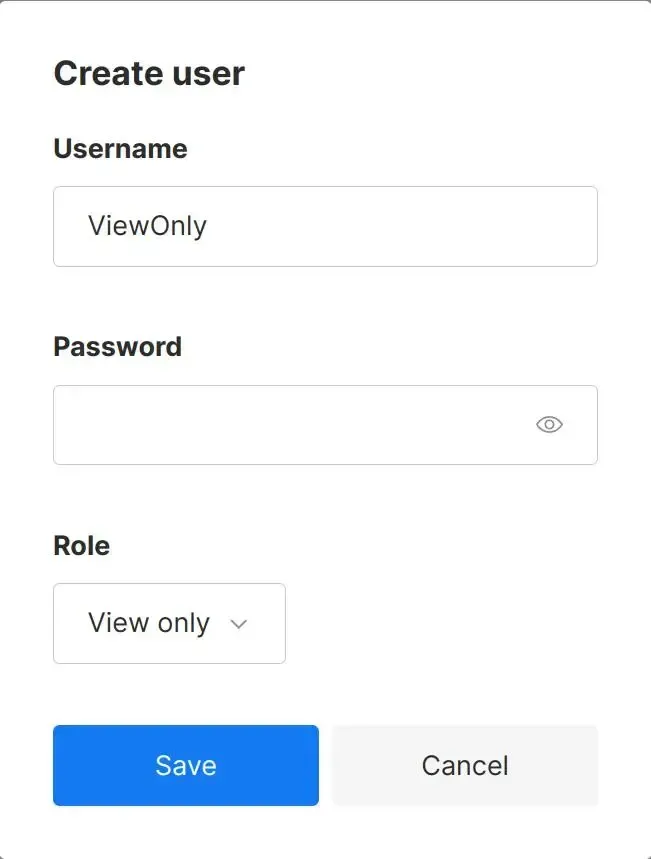
Q: 为什么不直接调用 Umami 的 API 获取数据,而是要额外创建一个账户?
A: 博客是 静态开源无服务器 的,所有代码都展示在前端,包括 API 调用。而 Umami 的
adminAPI 权限太大了,如果使用admin权限的 API Token,那么这个 token 可以获取、修改、删除所有网站的数据,会有严重的安全隐患。所以我们需要创建一个
View only权限的用户,使用这个低权限的用户的 API Token 来访问我们的浏览量等数据。
新建 Team 并添加用户和网站
Settings -> Teams -> Create team -> 填写名称 -> Save -> 找到刚刚创建的 Team -> Edit -> 复制 Access code,点击 Websites 中点击 Add website 选中你想共享的网站
换一个浏览器登录 Umami(使用View only 权限的用户) -> Settings -> Teams -> Join team -> 输入 Access code -> Join -> 如果没有出错的话,点击 Dashboard 就可以看到你刚刚添加的网站了
获取 View only 用户的 API Token
根据 Umami 的文档,我们可以通过以下方式获取 API Token:
POST /api/auth/login例如 你的网站地址为 example.com,那么你需要使用 View only 的账户密码向 https://example.com/api/auth/login 发送一个 POST 请求,请求体为:
{
"username": "your-username",
"password": "your-password"
}如果成功,你应该会得到以下的结果:
{
"token": "eyTMjU2IiwiY...4Q0JDLUhWxnIjoiUE_A",
"user": {
"id": "cd33a605-d785-42a1-9365-d6cad3b7befd",
"username": "your-username",
"createdAt": "2020-04-20 01:00:00"
}
}保存 token 值,并在所有请求中发送带 Bearer <token> 值的 Authorization 标头。请求标头应该如下所示:
Authorization: Bearer eyTMjU2IiwiY...4Q0JDLUhWxnIjoiUE_A发送请求获取数据
这里要用到类似于 postman 的 API 测试工具,可以使用的是开源的 hoppscotch,你也可以使用 curl 或者其他工具。
先分析一下官方文档的 API 接口:GET /api/websites/{websiteId}/stats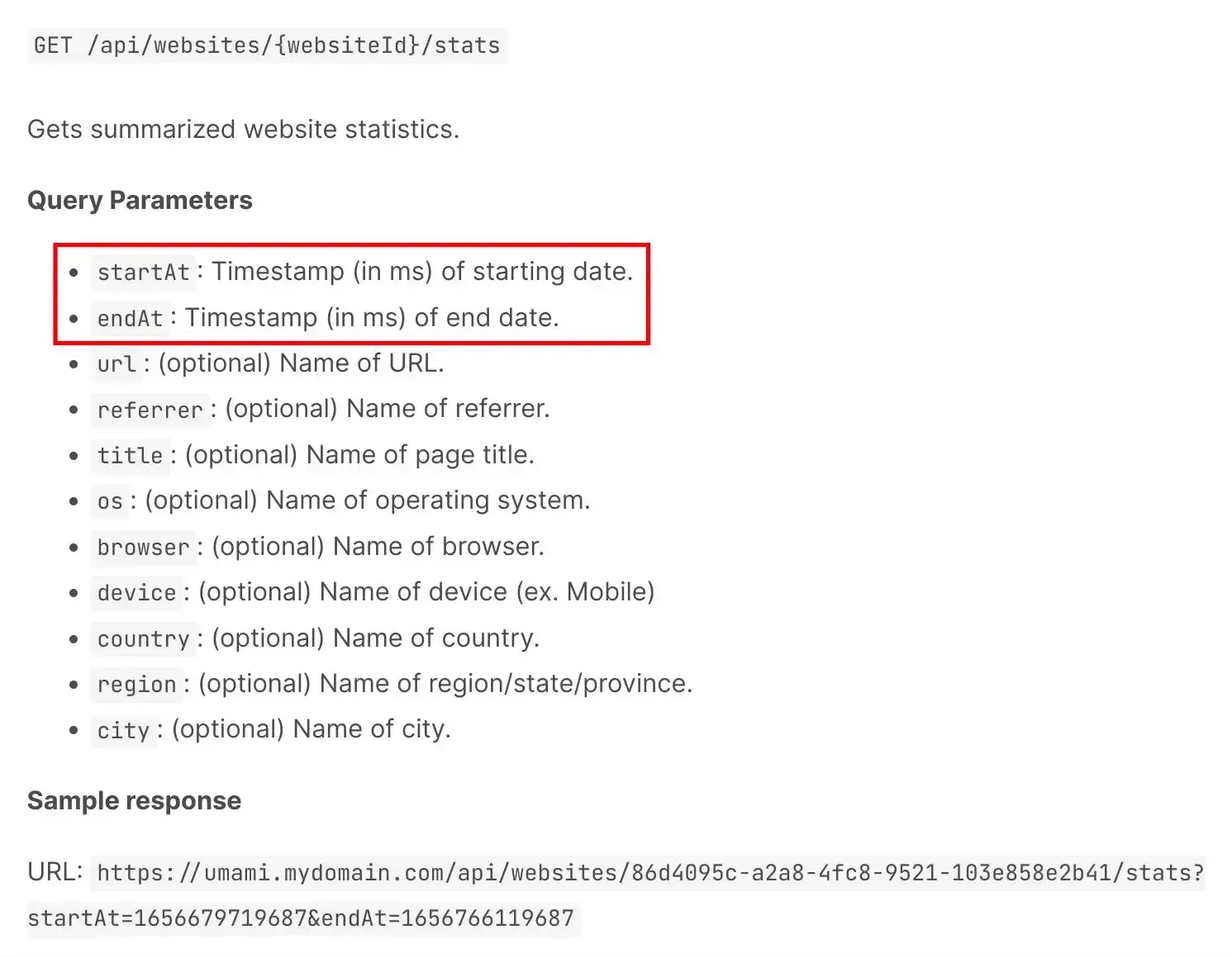
有两个必填的 查询参数:startAt 和 endAt,都是 Unix 毫秒时间戳,表示开始时间和结束时间
websiteId 和 startAt 需要我们自己获取
websiteId 可以在 Dashboard -> View details -> 看浏览器栏的地址 https://example.com/websites/{websiteId} 中找到
startAt 可发送 GET 请求到 https://example.com/api/websites/{websiteId},请求头为
Authorization: Bearer eyTMjU2IiwiY...4Q0JDLUhWxnIjoiUE_A在返回结果中找到 createdAt 字段,这个字段就是 startAt 的值,也就是你的网站创建时间,数据的开始时间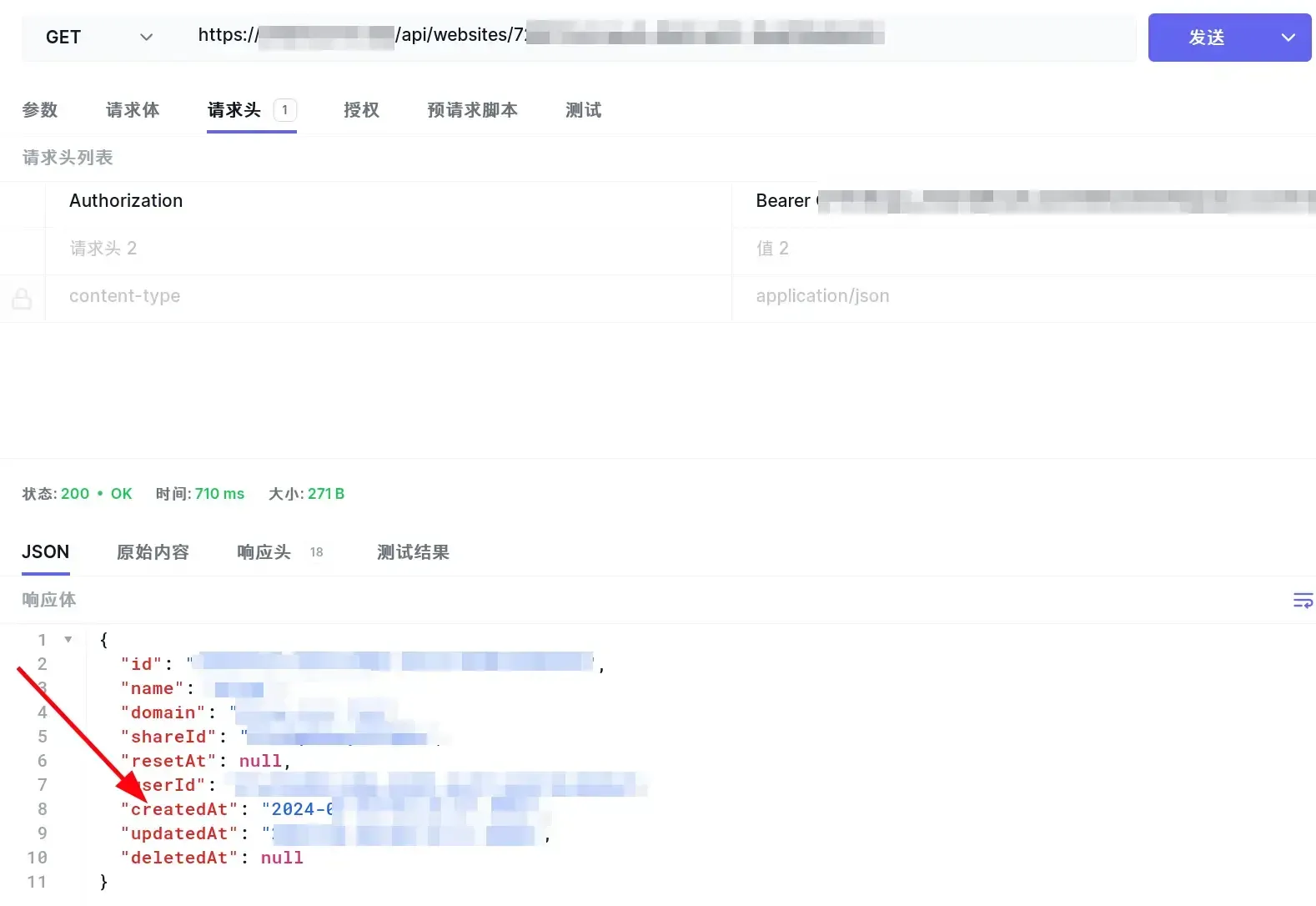
编写页面

代码如下,修改你对应的参数即可运行:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div style="text-align:center;">
<h1>Umami 网站统计</h1>
<span>总访问量 <span id="umami-site-pv"></span> 次</span>
<span>总访客数 <span id="umami-site-uv"></span> 人</span>
</div>
<script>
// 从配置文件中获取 umami 的配置
const website_id = 'xxx';
// 拼接请求地址
const request_url = 'https://xxx.com' + '/api/websites/' + website_id + '/stats';
const start_time = new Date('2024-01-01').getTime();
const end_time = new Date().getTime();
const token = 'xxxxxx';
// 检查配置是否为空
if (!website_id) {
throw new Error("Umami website_id is empty");
}
if (!request_url) {
throw new Error("Umami request_url is empty");
}
if (!start_time) {
throw new Error("Umami start_time is empty");
}
if (!token) {
throw new Error("Umami token is empty");
}
const params = new URLSearchParams({
startAt: start_time,
endAt: end_time,
});
const request_header = {
method: "GET",
headers: {
"Content-Type": "application/json",
"Authorization": "Bearer " + token,
},
};
async function allStats() {
try {
const response = await fetch(`${request_url}?${params}`, request_header);
const data = await response.json();
const uniqueVisitors = data.pageviews.value; // 获取独立访客数
const pageViews = data.pageviews.value; // 获取页面浏览量
let ele1 = document.querySelector("#umami-site-pv")
if (ele1) {
ele1.textContent = pageViews; // 设置页面浏览量
}
let ele2 = document.querySelector("#umami-site-uv")
if (ele2) {
ele2.textContent = uniqueVisitors;
}
console.log(uniqueVisitors, pageViews);
console.log(data);
} catch (error) {
console.error(error);
return "-1";
}
}
allStats();
</script>
</body>
</html>异步加载JS
方法:将JS文件的引入,放到HTML的body结束标签的上方
例:
<html>
<head>
<title>Hello World!</title>
</head>
<body>
xxxxx....
<script src="xx/xx.js"></script>
</body>
</html>原理:首先要明白,HTML的加载是从上往下一行一行解释执行的,把js文件的引入放到下面,这样就会先把HTML页面展示出来,然后再加载js。这样看起来的效果就是,大体的页面先出来,而js让它慢慢加载执行,如果你把js放到网页的上方,效果就是必须要加载完js才能继续展示网页,体验极差。
注意:原主题的js文件尽量不要动,我们只需将自己增加的一些js按照异步加载的方式做即可,比如一些音乐js插件、实时在线聊天js插件等放到最后即可!因为这些文件要加载的东西很多。
字蛛压缩字体
在上面我们介绍了如何在网站上引用自己喜欢的字体,但是这样会出现一个问题:字体文件太大!(尤其是中文,有时候为了几个字引入一个数十兆的字体文件,得不偿失),所有需要字体压缩!
使用场景
你的网站中需要自定义字体(额外添加一些普通电脑中没有的字体),但是一般字体是包含很多字符的,这就导致字体文件的体积很大
字蛛作用
字蛛就是自动检测网站的 CSS 与 HTML 文件中的自定义字体(额外加的字体),并将网站中用到的文字重新打包成一个新的字体文件,并自动引入;
而没用到的文字就会删除,从而达到压缩字体文件体积的作用。
安装
npm install font-spider -g在 CSS 中使用 WebFont:
/*声明 WebFont*/
@font-face {
font-family: 'pinghei';
src: url('../font/pinghei.eot');
src:
url('../font/pinghei.eot?#font-spider') format('embedded-opentype'),
url('../font/pinghei.woff') format('woff'),
url('../font/pinghei.ttf') format('truetype'),
url('../font/pinghei.svg') format('svg');
font-weight: normal;
font-style: normal;
}
/*使用选择器指定字体*/
.home h1, .demo > .test {
font-family: 'pinghei';
}
- @font-face 中的 src 定义的 .ttf 文件必须存在,其余的格式将由工具自动生成
- 开发阶段请使用相对路径的 CSS 与 WebFont
运行 font-spider 命令:
font-spider ./demo/*.html页面依赖的字体将会自动压缩好,原 .ttf 字体会备份
使用 FontForge 压缩 Font awesome
曾经尝试过各种方案来压缩字体,最后还是这种方法最适合
下载安装 FontForge
准备python 环境
minify.py 文件
import glob
import re
import fontforge
extensions = [".html", ".js"]
pattern = re.compile("(fa-[-\w]+)")
# 获取使用到的图标
def get_used_icons(path):
icon_dict = {}
for filename in glob.glob(path, recursive=True):
for extension in extensions:
if extension in filename:
for line in open(filename, encoding='utf-8'):
for match in re.finditer(pattern, line):
icon_dict[match.group()[3:]] = True
return icon_dict
# 去除除了传入的字典的图标
def minify(path, used_dict):
font = fontforge.open(path)
assert isinstance(font, fontforge.font)
selection = font.selection
assert isinstance(selection, fontforge.selection)
selection.all()
for i in selection.byGlyphs:
assert isinstance(i, fontforge.glyph)
if i.glyphname not in used_dict:
font.removeGlyph(i)
font.generate(path)
if __name__ == '__main__':
web_path = "V:/hexo/blog/public/**"
font_path = "V:/hexo/blog/themes/matery/source/libs/awesome/webfonts/"
font_list = ["fa-brands-400.woff2", "fa-regular-400.woff2", "fa-solid-900.woff2"]
used_icon_dict = get_used_icons(web_path)
for font_name in font_list:
minify(font_path + font_name, used_icon_dict)import glob
import re
import fontforge
import os
extensions = [".html", ".js"]
pattern = re.compile(r"(fa-[-\w]+)")
user_defined_icons = ["fa-github", "fa-pencil", "fa-cog", "fa-cloud-upload", "fa-compress-arrows-alt"]
# 获取使用到的图标
def get_used_icons(path):
icon_dict = {}
for filename in glob.glob(path, recursive=True):
for extension in extensions:
if extension in filename:
with open(filename, encoding="utf-8") as file:
for line in file:
for match in re.finditer(pattern, line):
icon_dict[match.group()[3:]] = True
return icon_dict
# 去除除了传入的字典的图标
def minify(source_path, target_path, used_dict):
font = fontforge.open(source_path)
assert isinstance(font, fontforge.font)
selection = font.selection
assert isinstance(selection, fontforge.selection)
selection.all()
for i in selection.byGlyphs:
assert isinstance(i, fontforge.glyph)
if i.glyphname not in used_dict:
font.removeGlyph(i)
font.generate(target_path)
font.close()
if __name__ == '__main__':
web_path = "V:/hexo/blog/public/**/*"
font_source_dir = "V:/hexo/blog/themes/matery/source/libs/awesome5/webfonts/"
font_target_dir = "V:/hexo/blog/themes/matery/source/libs/awesome/webfonts/"
font_list = ["fa-brands-400.woff2", "fa-regular-400.woff2", "fa-solid-900.woff2"]
used_icon_dict = get_used_icons(web_path)
# Add user-defined icons to the used icons dictionary
for icon in user_defined_icons:
used_icon_dict[icon] = True
print("Used Icons:")
for icon in used_icon_dict.keys():
print(icon)
for font_name in font_list:
source_path = os.path.join(font_source_dir, font_name)
target_path = os.path.join(font_target_dir, font_name)
minify(source_path, target_path, used_icon_dict)
下面是一个增强版本
import glob
import re
import fontforge
import os
extensions = [".html", ".js"]
pattern = re.compile(r"(fa-[-\w]+)")
user_defined_icons = ["fa-github", "fa-pencil", "fa-cog", "fa-cloud-upload"]
# 获取使用到的图标
def get_used_icons(path):
icon_dict = {}
for filename in glob.glob(path, recursive=True):
for extension in extensions:
if extension in filename:
with open(filename, encoding="utf-8") as file:
for line in file:
for match in re.finditer(pattern, line):
icon_dict[match.group()[3:]] = True
return icon_dict
# 去除除了传入的字典的图标
def minify(source_path, target_path, used_dict):
font = fontforge.open(source_path)
assert isinstance(font, fontforge.font)
selection = font.selection
assert isinstance(selection, fontforge.selection)
selection.all()
for i in selection.byGlyphs:
assert isinstance(i, fontforge.glyph)
if i.glyphname not in used_dict:
font.removeGlyph(i)
font.generate(target_path)
font.close()
if __name__ == '__main__':
web_path = "V:/hexo/blog/public/**/*"
font_source_dir = "V:/hexo/blog/themes/matery/source/libs/awesome5/webfonts/"
font_target_dir = "V:/hexo/blog/themes/matery/source/libs/awesome/webfonts/"
font_list = ["fa-brands-400.woff2", "fa-regular-400.woff2", "fa-solid-900.woff2"]
used_icon_dict = get_used_icons(web_path)
# Add user-defined icons to the used icons dictionary
for icon in user_defined_icons:
used_icon_dict[icon] = True
print("Used Icons:")
for icon in used_icon_dict.keys():
print(icon)
for font_name in font_list:
source_path = os.path.join(font_source_dir, font_name)
target_path = os.path.join(font_target_dir, font_name)
minify(source_path, target_path, used_icon_dict)
运行压缩
Windows下只能通过font forge自带的解释器了,打开这个FontForge interactive console。
D:\Program Files (x86)\FontForgeBuilds>bin\ffpython.exe d:\Work\Dev\minifyFont\minify.py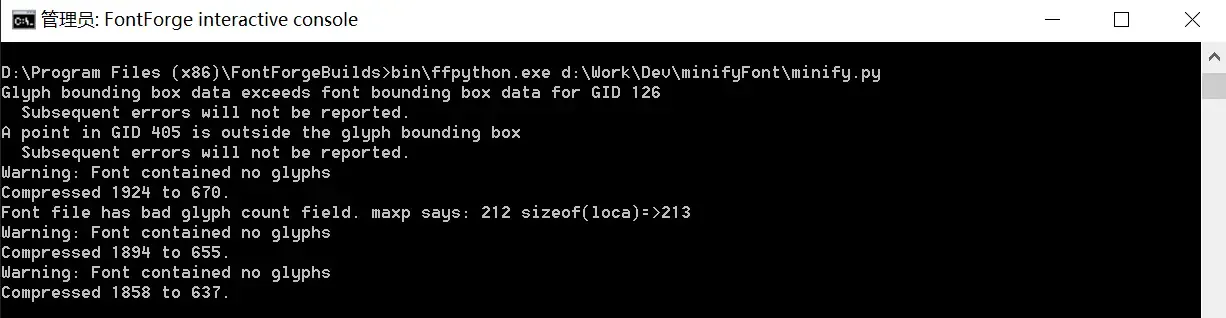
只在 font awesome v5 上面测试成功! V6 运行失败
使用webp图像格式来优化大小
把所有图像都转换为webp格式,可以极大减小图片体积,加快加载速度。
图片懒加载
图片懒加载是提升网站性能和用户体验的一个非常很好方式,并且几乎所有的大型网站都使用到了,比如微博,仅把用户可见的部分显示图片,其余的都暂时不加载,做法就是:让所有图片元素src指向一个小的站位图片比如loading,并新增一个属性(如data-original)存放真实图片地址。每当页面加载(或者滚动条滚动),使用JS脚本将可视区域内的图片src替换回真实地址,并做请求重新加载。
- Don’t worry about lazyload SEO problem, because Google supports it already.
那么,赶快用起来吧!
在站点根目录执行下面的命令:
npm install hexo-lazyload-image --save
#或者使用yarn
yarn add hexo-lazyload-image之后在站点配置文件下添加下面的代码
lazyload:
enable: true # 是否开启图片懒加载
onlypost: false # 是否只对文章的图片做懒加载
loadingImg: # eg ./images/loading.gif
isSPA: false # optional. For performance considering, isSPA is added. If your theme is a SPA page, please set it as true
preloadRatio: 3 # optional, default is 1最后执行 hexo clean && hexo g && hexo s 就可以看到效果了。
存在问题:
查看大图,发现全部为 loading 加载图,原因是因为懒加载插件与 lightgallery 插件冲突,解决办法如下:
修改主题文件下的 matery.js,在 108 行左右添加以下代码:
$(document).find('img[data-original]').each(function(){
$(this).parent().attr("href", $(this).attr("data-original"));
});specify no-lazy for specify image
we can also disable the lazy process if specify a attribute on img tag in both markdown or html
<img no-lazy src="abc.png" />
Hexo-lazy-image 实现原理
因为文章都是使用markdown来编写的,所以不可能要求我们在markdown里将所有图片路径都指向站位图片,并附加另一个属性,所以,这个工作必须留给hexo的generate部分来做。
最终可分为两步:
- 在hexo after_post_render事件或者after_render:html事件里将生产出来的文章html代码中所有img元素都加上 data-original 属性,并把src值付给他, 然后在将src值致为loading图片
- 注入simple-lazyload脚本在每个页面最后面,当页面加载过后负责判定当前需要重新加载的图片。
这里重点提提正则表达式,在对第一步替换的时候,只是使用了简单的正则表达式去匹配查找所有的img节点,后来发现不仅如此,正则表达式结合string.replace更是如此强大。
return htmlContent.replace(/<img(\s*?)src="(.*?)"(.*?)>/gi, function (str, p1, p2) {
return str.replace(p2, loadingImage + '" data-original="' + p2);
})另一种懒加载,需要自定义修改的比较多 vanilla-lazyload
博客写作工具
FFMpeg
将小视频转换成GIF动图
那么,如何能够将一个完整小视频,或一个长视频的某一部分转化成GIF动图呢?这里要使用一种多媒体工具:ffmpeg.
想将整个视频转换成GIF,你可以使用下面的命令:
ffmpeg -i small.mp4 small.gif想将一个视频里的指定的时间段转换成GIF,你可以使用下面的命令:
ffmpeg -t 3 -ss 00:00:02 -i small.webm small-clip.gif上面的命令是利用ffmpeg将从视频第二秒开始、时长为3秒的片段提取出、并转化成GIF动图。
如果各种参数保持缺省值,则转换后的图像的清晰度、分辨率并不是特别高,但这些参数你可以任意设置:
ffmpeg -i small.mp4 -b 2048k small.gif将GIF动图转换成视频
命令行的写法非常相似而简单:
ffmpeg -f gif -i animation.gif animation.mp4这个命令还可以让你选择性的将GIF图转换成各种视频格式:
ffmpeg -f gif -i animation.gif animation.mpeg
ffmpeg -f gif -i animation.gif animation.webm将MP4、MPEG、MOV等格式的视频转换成WEBM格式的方法
ffmpeg -i trailer.mov -c:v libvpx -crf 10 -b:v 1M -c:a libvorbis trailer.webm让Apache Servers支持WEBM格式
因为WEBM是一种新的文件格式,你需要让Apache服务器认识这种后缀。下面就是通过修改.htaccess来让Apache支持它:
AddType video/webm webm用gifsicle优化GIF动图
大部分的GIF动图都是要放在网页上,最终下载到用户的浏览器里,所以,优化这些GIF图片的体积是十分必要的,这里我们就需要用到另外一个非常有用的GIF图片修改工具:gifsicle,它有一个内置的方法能够优化GIF动图的体积。
在开始介绍对GIF图片的优化方法前,你需要知道的一点是,gifsicle不仅仅是GIF图片优化工具。gifsicle还可以调整GIF图片的大小,合并多个GIF动图等等任何你能想到的对GIF图片的操作。
gifsicle 对GIF图片有三种优化选项:
-O1只保存每张图像上变化的部分。这是缺省模式。-O2进一步用透明度压缩图片。-O3尝试各种优化方法(通常速度会慢一些,有时会产生更好的效果)。
优化GIF动图的命令行写法是这样的:
gifsicle -O3 animation.gif -o animation-optimized.gif如果你有耐心和时间,推荐你尝试一下-O3,它有可能会给你输出体积更小的GIF动图。
hexo插件hexo-minify
Hexo-minify 是一款 Hexo 压缩插件,它可以压缩 HTML、CSS、JS
安装
npm install hexo-minify --save说明
如需修改,可在Hexo配置文件内编辑覆盖 如果仅安装插件,并未填写相关配置,则使用默认配置信息
默认配置信息
## Hexo-minify Default Config Options
minify:
js:
enable: true
## 详细配置: https://github.com/mishoo/UglifyJS
options:
css:
enable: true
## 详细配置: https://github.com/clean-css/clean-css#compatibility-modes
options:
html:
enable: true
## 详细配置: https://github.com/kangax/html-minifier#options-quick-reference
options:
minifyJS: true # Compressed JavaScript
minifyCSS: true # CSS Compressed
removeComments: true # Remove the comments
collapseWhitespace: true # Delete any extra space
removeAttributeQuotes: true # Delete attribute quotes
# + 1.2.0 版本新增
postcss:
enable: true
## 详细配置: https://github.com/postcss/autoprefixer#options
## 注意Hexo-minify仅内置了autoprefixer插件
## 受Hexo限制,目前无法实现自定义postcss插件
options:
# JavaScript 数组写法
# overrideBrowserslist: ['> 1%', 'last 2 versions', 'not dead']
# YAML 数组写法
overrideBrowserslist:
- '> 1%' # 特殊符号需要使用'或"
- last 2 versions
- not deadhexo插件hexo-filter-lqip
- hexo-filter-lqip
- A Hexo plugins which helps to introduce low quality image placeholders to the theme
- 不支持hexo5.x以上版本,可以强制安装
-f,实现方法可以借鉴
Installation
npm i hexo-filter-lqip --saveUsage
Install this plugin for the theme and use the view helper to render a placeholder.
lqipFor view helper
lqipFor(path_to_asset, options)String *path_to_asset - a path to the image
Object
options
- String [type] - a type of placeholder, see the list of available types, defaults to the
default_typeas configured
- String [type] - a type of placeholder, see the list of available types, defaults to the
Returns a CSS value for background-image property, which is a simplified version of the original image.
Example for EJS
<div
style="background-image: <%- lqip_for('/content/my-photo.jpg') %>"
></div>iframe Lazy Loading
现代浏览器
支持 loading 参数,让浏览器滚动到 iframe 附近再价值啊 iframe
<iframe src="https://blog.17lai.site" loading="lazy" />loading 参数:
lazy: good candidate for lazy-loadingeager: not a good candidate for lazy-loading, loads right awayauto: the browser determines whether or not to lazily load
老旧浏览器兼容
检查 HTMLIFrameElement 是否有 loading 属性
if ('loading' in HTMLIFrameElement.prototype) {
// Native image lazy-loading is available
} else {
// Use polyfill or a 3rd-party library
}完整代码
<iframe class="lazyload" data-src="https://blog.17lai.site">
</iframe>if ('loading' in HTMLIFrameElement.prototype) {
const iframes = document.querySelectorAll('iframe[loading="lazy"]');
iframes.forEach(iframe => {
iframe.src = iframe.dataset.src;
});
} else {
// Dynamically import the LazySizes library
const script = document.createElement('script');
script.src =
'https://cdnjs.cloudflare.com/ajax/libs/lazysizes/5.2.2/lazysizes.min.js';
document.body.appendChild(script);
}jquery lazyloading
Jquery 实现的按键加载 iframe
var iframes = $('iframe');
$('button').click(function() {
iframes.attr('src', function() {
return $(this).data('src');
});
});
iframes.attr('data-src', function() {
var src = $(this).attr('src');
$(this).removeAttr('src');
return src;
});gulp 体积压缩
- 减小体积,加快加载速度
- 因为 hexo 生成的 html、css、js 等都有很多的空格或者换行,而空格和换行也是占用字节的,所以需要将空格换行去掉也就是我要进行的 “压缩”。
npm install gulp -g
# 安装各种小功能模块 执行这步的时候,可能会提示权限的问题,最好以管理员模式执行
npm install gulp gulp-htmlclean gulp-htmlmin gulp-minify-css gulp-uglify gulp-imagemin --save
# 额外的功能模块
npm install gulp-debug gulp-clean-css gulp-changed gulp-if gulp-plumber gulp-babel babel-preset-es2015 del @babel/core --save
或者使用yarn
yarn global add gulp
yarn add gulp gulp-htmlclean gulp-htmlmin gulp-minify-css gulp-uglify gulp-imagemin
yarn add gulp-debug gulp-clean-css gulp-changed gulp-if gulp-plumber gulp-babel babel-preset-es2015 del @babel/core
- npm下载太慢怎么办? 修改国内淘宝源加速,戳
然后,在根目录新增 gulpfile.js :
var gulp = require("gulp");
var debug = require("gulp-debug");
var cleancss = require("gulp-clean-css"); //css压缩组件
var uglify = require("gulp-uglify"); //js压缩组件
var htmlmin = require("gulp-htmlmin"); //html压缩组件
var htmlclean = require("gulp-htmlclean"); //html清理组件
var imagemin = require("gulp-imagemin"); //图片压缩组件
var changed = require("gulp-changed"); //文件更改校验组件
var gulpif = require("gulp-if"); //任务 帮助调用组件
var plumber = require("gulp-plumber"); //容错组件(发生错误不跳出任务,并报出错误内容)
var isScriptAll = true; //是否处理所有文件,(true|处理所有文件)(false|只处理有更改的文件)
var isDebug = true; //是否调试显示 编译通过的文件
var gulpBabel = require("gulp-babel");
var es2015Preset = require("babel-preset-es2015");
var del = require("del");
var Hexo = require("hexo");
var hexo = new Hexo(process.cwd(), {}); // 初始化一个hexo对象
// 清除public文件夹
gulp.task("clean", function () {
return del(["public/**/*"]);
});
// 下面几个跟hexo有关的操作,主要通过hexo.call()去执行,注意return
// 创建静态页面 (等同 hexo generate)
gulp.task("generate", function () {
return hexo.init().then(function () {
return hexo
.call("generate", {
watch: false
})
.then(function () {
return hexo.exit();
})
.catch(function (err) {
return hexo.exit(err);
});
});
});
// 启动Hexo服务器
gulp.task("server", function () {
return hexo
.init()
.then(function () {
return hexo.call("server", {});
})
.catch(function (err) {
console.log(err);
});
});
// 部署到服务器
gulp.task("deploy", function () {
return hexo.init().then(function () {
return hexo
.call("deploy", {
watch: false
})
.then(function () {
return hexo.exit();
})
.catch(function (err) {
return hexo.exit(err);
});
});
});
// 压缩public目录下的js文件
gulp.task("compressJs", function () {
return gulp
.src(["./public/**/*.js", "!./public/libs/**"]) //排除的js
.pipe(gulpif(!isScriptAll, changed("./public")))
.pipe(gulpif(isDebug, debug({ title: "Compress JS:" })))
.pipe(plumber())
.pipe(
gulpBabel({
presets: [es2015Preset] // es5检查机制
})
)
.pipe(uglify()) //调用压缩组件方法uglify(),对合并的文件进行压缩
.pipe(gulp.dest("./public")); //输出到目标目录
});
// 压缩public目录下的css文件
gulp.task("compressCss", function () {
var option = {
rebase: false,
//advanced: true, //类型:Boolean 默认:true [是否开启高级优化(合并选择器等)]
compatibility: "ie7" //保留ie7及以下兼容写法 类型:String 默认:''or'*' [启用兼容模式; 'ie7':IE7兼容模式,'ie8':IE8兼容模式,'*':IE9+兼容模式]
//keepBreaks: true, //类型:Boolean 默认:false [是否保留换行]
//keepSpecialComments: '*' //保留所有特殊前缀 当你用autoprefixer生成的浏览器前缀,如果不加这个参数,有可能将会删除你的部分前缀
};
return gulp
.src(["./public/**/*.css", "!./public/**/*.min.css"]) //排除的css
.pipe(gulpif(!isScriptAll, changed("./public")))
.pipe(gulpif(isDebug, debug({ title: "Compress CSS:" })))
.pipe(plumber())
.pipe(cleancss(option))
.pipe(gulp.dest("./public"));
});
// 压缩public目录下的html文件
gulp.task("compressHtml", function () {
var cleanOptions = {
protect: /<\!--%fooTemplate\b.*?%-->/g, //忽略处理
unprotect: /<script [^>]*\btype="text\/x-handlebars-template"[\s\S]+?<\/script>/gi //特殊处理
};
var minOption = {
collapseWhitespace: true, //压缩HTML
collapseBooleanAttributes: true, //省略布尔属性的值 <input checked="true"/> ==> <input />
removeEmptyAttributes: true, //删除所有空格作属性值 <input id="" /> ==> <input />
removeScriptTypeAttributes: true, //删除<script>的type="text/javascript"
removeStyleLinkTypeAttributes: true, //删除<style>和<link>的type="text/css"
removeComments: true, //清除HTML注释
minifyJS: true, //压缩页面JS
minifyCSS: true, //压缩页面CSS
minifyURLs: true //替换页面URL
};
return gulp
.src("./public/**/*.html")
.pipe(gulpif(isDebug, debug({ title: "Compress HTML:" })))
.pipe(plumber())
.pipe(htmlclean(cleanOptions))
.pipe(htmlmin(minOption))
.pipe(gulp.dest("./public"));
});
// 压缩 public/medias 目录内图片
gulp.task("compressImage", function () {
var option = {
optimizationLevel: 5, //类型:Number 默认:3 取值范围:0-7(优化等级)
progressive: true, //类型:Boolean 默认:false 无损压缩jpg图片
interlaced: false, //类型:Boolean 默认:false 隔行扫描gif进行渲染
multipass: false //类型:Boolean 默认:false 多次优化svg直到完全优化
};
return gulp
.src("./public/medias/**/*.*")
.pipe(gulpif(!isScriptAll, changed("./public/medias")))
.pipe(gulpif(isDebug, debug({ title: "Compress Images:" })))
.pipe(plumber())
.pipe(imagemin(option))
.pipe(gulp.dest("./public"));
});
// 执行顺序: 清除public目录 -> 产生原始博客内容 -> 执行压缩混淆 -> 部署到服务器
gulp.task(
"cicd",
gulp.series(
"clean",
"generate",
"compressHtml",
"compressCss",
"compressJs",
"compressImage",
gulp.parallel("deploy")
)
);
gulp.task(
"ci",
gulp.series(
"clean",
"generate",
gulp.parallel("compressHtml", "compressCss", "compressJs","compressImage")
)
);
// 默认任务
gulp.task(
"default",
gulp.series(
gulp.parallel("compressHtml", "compressCss", "compressJs","compressImage")
)
);
//Gulp4最大的一个改变就是gulp.task函数现在只支持两个参数,分别是任务名和运行任务的函数运行:
hexo clean && hexo g && gulp && hexo g直接在 Hexo 根目录执行 gulp ci,这个命令相当于 hexo cl&&hexo g 并且再把代码和图片压缩。 在 Hexo 根目录执行 gulp cicd ,这个命令与 gulp ci相比是:在最后又加了个 hexo d ,等于说生成、压缩文件后又帮你自动部署了
如果不想用图片压缩可以把"compressImage" 去掉即可
Docker版Imagin
使用Docker版本的imagemin来压缩图片!一行命令搞定!
gulp-imagemin相关的依赖,以及配置太TMD复杂了,博主新的Docker里面配置很久没搞定,虽然以前搞定过,囧rz! 如是去找了一下Docker镜像,立马搞定!
docker run -v `pwd`:/work mitakeck/imagemin
Python图片无损压缩
jpg,png.webp图片无损压缩工具!说明去项目主页看。有中文说明。
最近作者更新了新版本,以前bug都解决了,使用完美!
使用教程O(∩_∩)O
git clone https://github.com/xinlin-z/smally.git
cd smally
git checkout newstart
sudo bash install_tools.sh
# Run Test
bash test.sh
# Usage
find <path/to/image_folder> -type f -exec bash smally.sh {} \;本地搜索优化
html、css和js都压缩了,很开心。但是,还有一个大文件没有压缩,就是本地搜索的DB文件search.xml。这个search.xml文件的大小为7.5M,很大。打开search.xml文件,发现里面不止包含文章内容,还包含html标签。参考hexo-generator-searchdb,发现可以设置不生成标签。
- 修改hexo/_config.yml的localsearch配置为:
# local search
search:
path: search.xml
field: post
format: striptags
limit: 10000- 重新生成search.xml文件
- 还可以给search.xml添加上jsdelivr cdn 加速!
本教程还有其它五大部分,更多内容请见Hexo系列教程
系列教程
Hexo系列
[十万字图文教程]基于Hexo的matery主题搭建博客并深度优化完全一站式教程
- Hexo Docker环境与Hexo基础配置篇
- hexo博客自定义修改篇
- hexo博客网络优化篇
- hexo博客增强部署篇
- hexo博客个性定制篇
- hexo博客常见问题篇
- hexo博客博文撰写篇之完美笔记大攻略终极完全版
- Hexo Markdown以及各种插件功能测试
- markdown 各种其它语法插件,latex公式支持,mermaid图表,plant uml图表,URL卡片,bilibili卡片,github卡片,豆瓣卡片,插入音乐和视频,插入脑图,插入PDF,嵌入iframe
- 在 Hexo 博客中插入 ECharts 动态图表
- 使用nodeppt给hexo博客嵌入PPT演示
- GithubProfile美化与自动获取RSS文章教程
- Vercel部署高级用法教程
- webhook部署Hexo静态博客指南
- 在宝塔VPS上面采用docker部署waline全流程图解教程
- 自建Umami访问统计服务并统计静态博客UV/PV
笔记系列
- 完美笔记进化论
- hexo博客博文撰写篇之完美笔记大攻略终极完全版
- Joplin入门指南&实践方案
- 替代Evernote免费开源笔记Joplin-网盘同步笔记历史版本Markdown可视化
- Joplin 插件以及其Markdown语法。All in One!
- Joplin 插件使用推荐
- 为知笔记私有化Docker部署
Gitbook使用系列
- GitBook+GitLab撰写发布技术文档-Part1:GitBook篇
- GitBook+GitLab撰写发布技术文档-Part2:GitLab篇
- 自己动手制作电子书的最佳方式(支持PDF、ePub、mobi等格式)


